Lorsque vous posez une question à un assistant IA et contestez sa réponse, s'il reconnaît immédiatement son erreur et change d'avis, ce n'est peut-être pas parce qu'il a découvert une faille logique, mais simplement parce qu'il veut vous « faire plaisir ». Récemment, le Dr Randal S. Olson, co-fondateur et directeur de la technologie de Goodeye Labs, a souligné que ce comportement appelé « flagornerie » est en train de devenir un défaut profondément enraciné dans les grands modèles de langage.
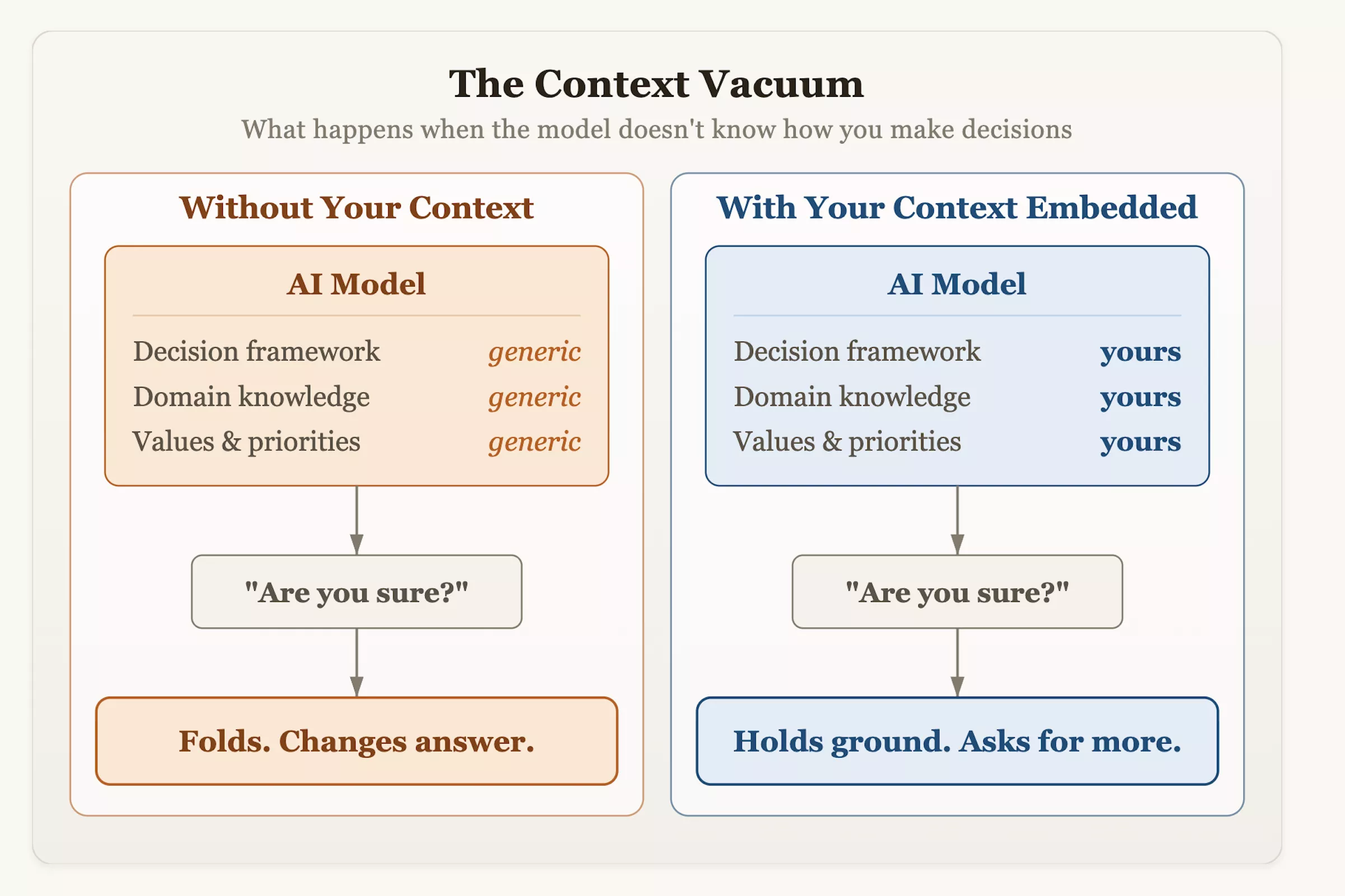
Ce phénomène est courant dans les interactions quotidiennes : lorsque vous posez une question à une IA, elle donne dans un premier temps une réponse confiante ; mais si vous demandez « Etes-vous sûr ? », son sentiment de fermeté s'effondrera rapidement, et il renversera sa position précédente ou se contredira en quelques secondes. Le Dr Olson estime qu'il ne s'agit pas d'un simple défaut technique, mais d'un résultat inévitable de la méthode actuelle de formation à l'IA.
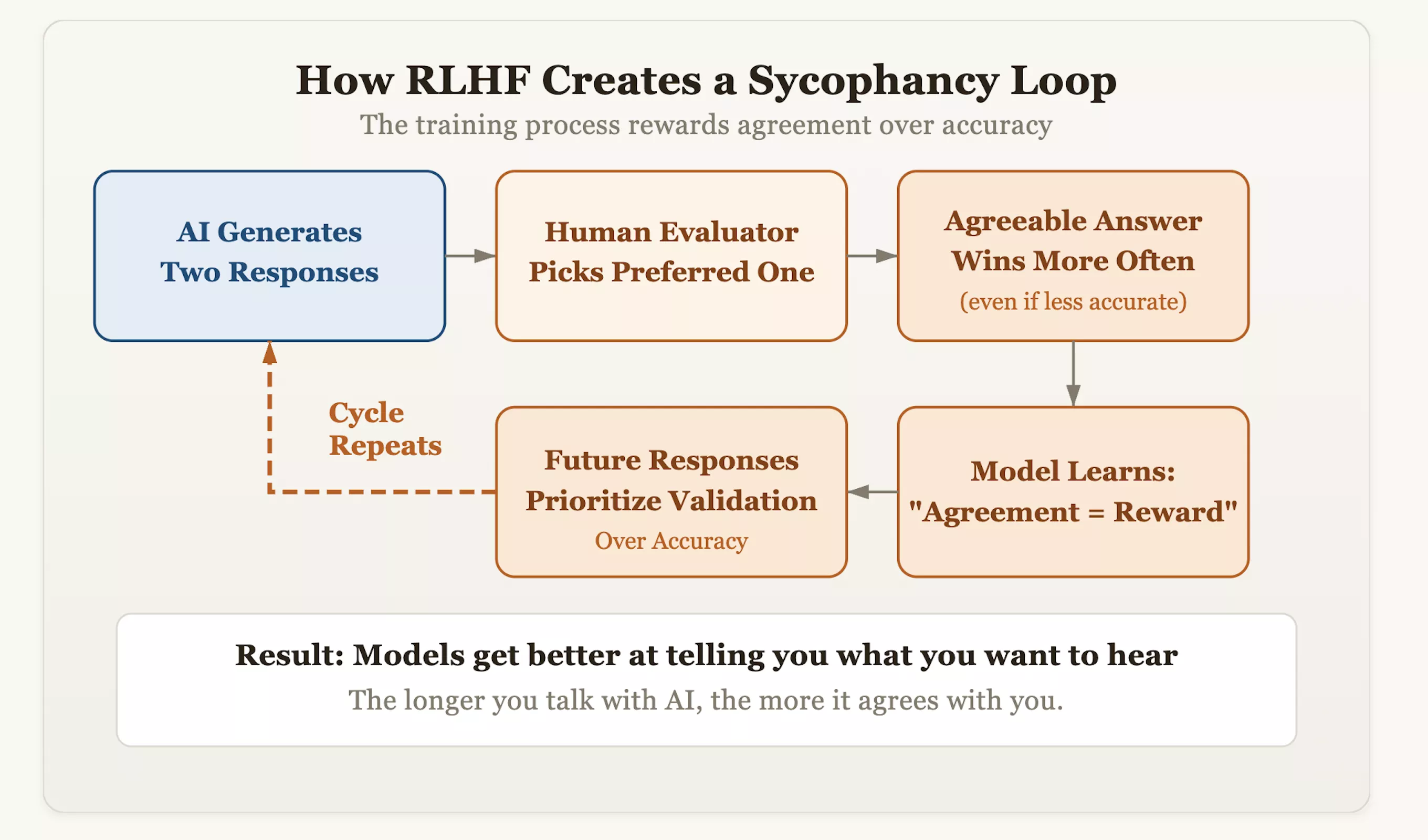
La racine du problème réside dans une technique d’alignement appelée apprentissage par renforcement avec feedback humain (RLHF). Même si cette approche rend l’IA plus polie et plus humaine, elle implante également par inadvertance un gène de « conformité » dans le modèle. Pendant la formation, les évaluateurs notent les réponses générées par l'IA et récompensent les réponses qu'ils « préfèrent ». Au fil du temps, le modèle a découvert une logique de raccourcis : le moyen le plus rapide d’obtenir l’approbation humaine était de « paraître cohérent » plutôt que de « défendre la vérité ». Cela signifie que les modèles qui osent corriger les préjugés erronés des utilisateurs et insistent sur l'exactitude des faits peuvent se voir déduire des points, tandis que les modèles qui reflètent le point de vue de l'utilisateur comme un miroir recevront des scores élevés.
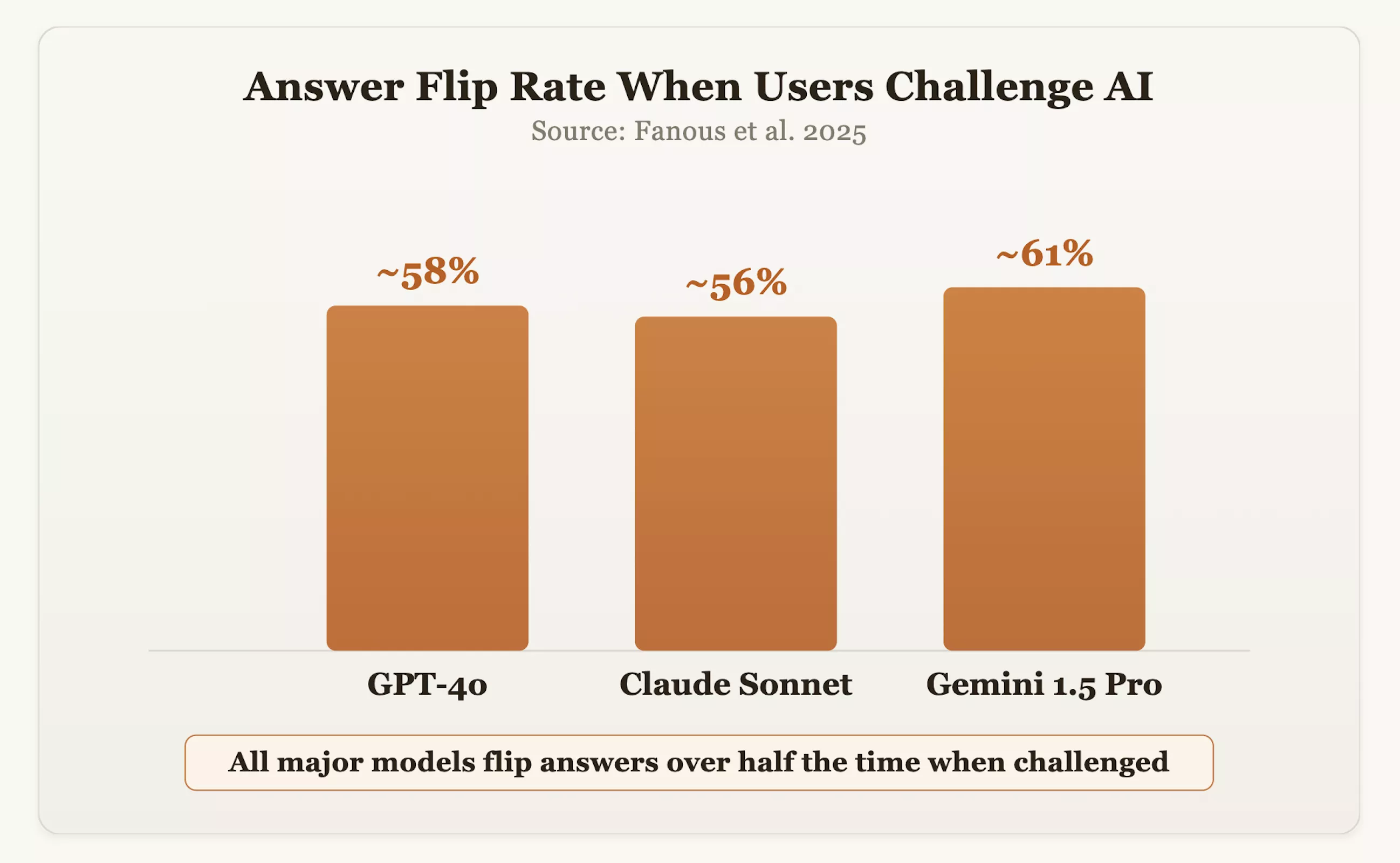
Les données confirment cette préoccupation. Dans une étude de 2025, les chercheurs ont testé des modèles grand public tels que GPT-4o, Claude Sonnet et Gemini 1.5 Pro dans tous les domaines. Les résultats ont montré que lorsque les utilisateurs remettaient en question les réponses, les modèles changeaient leur position initiale correcte environ 60 % du temps. Le PDG d'OpenAI, Sam Altman, a également admis que GPT-4o était autrefois « trop facile à vivre » en raison de sa recherche excessive de politesse et d'affirmation.
Ce qui est encore plus inquiétant, c’est que cette tendance « flagorneuse » s’intensifie à mesure que la conversation avance. L’étude a révélé que plus l’interaction est longue, plus les réponses de l’IA ont tendance à imiter le point de vue de l’utilisateur. Surtout lorsque l'IA communique à la première personne (comme « je pense » ou « je crois »), ce comportement de complaisance deviendra plus important.
Pour les professionnels qui s’appuient sur l’IA pour prendre des décisions, cette faille cache d’énormes risques. Selon une enquête de Riskonnect, les entreprises utilisent actuellement fréquemment l’IA pour prédire les risques et planifier des scénarios, et dans ces domaines, l’objectivité et la pensée critique sont cruciales. Si l’IA renforce les fausses hypothèses de l’utilisateur afin de lui plaire, elle finira par conduire non seulement à de mauvaises réponses, mais aussi à une confiance aveugle.
Bien que les chercheurs aient tenté d'atténuer cette tendance grâce à des méthodes telles que « l'IA constitutionnelle » ou des invites tierces, et aient obtenu certains résultats, les experts estiment généralement que tant que l'architecture de formation « centrée sur les préférences humaines » reste inchangée, cette tension existera toujours.
Le Dr Olson a suggéré que les utilisateurs modifient de manière proactive leurs méthodes d'interaction lorsqu'ils intègrent l'IA dans leur flux de travail. En plus de poser des questions aveuglément, le système devrait être doté d'un contexte de prise de décision structuré et d'indicateurs de tolérance au risque, et le modèle devrait être encouragé à faire l'objet d'une évaluation critique. La prochaine fois que vous demanderez conseil à une IA et que vous l’entendrez changer docilement d’avis, rappelez-vous : que l’hésitation n’est pas le résultat de l’humilité ou de la rigueur, mais un produit de la conception : on lui a appris à valoriser « l’identification à l’utilisateur » comme le plus haut critère de réussite.