Cette fois, l’ingénierie logicielle humaine s’est faite « à l’envers » ! Tout à l'heure, le blog officiel d'OpenAI a exposé l'une de leurs expériences internes : une première équipe de trois ingénieurs a utilisé l'agent Codex pour créer un « produit de code d'un million de lignes » à partir de zéro en cinq mois. Pendant tout le processus, les humains n'écrivent pas de code manuellement, mais se concentrent sur « réfléchir clairement à ce qu'ils veulent et établir des règles », et laissent tout le reste à l'IA.
Chaque personne peut envoyer en moyenne 3,5 PR (Pull Requests, demandes de fusion de code) chaque jour, et l'ensemble du processus d'exécution des PR (implémentation, tests, documentation, configuration CI) est géré par des agents.
OpenAI a donné à ce workflow un nom très vivant : « Harness Engineering ».

https://openai.com/index/harness-engineering/
Dans l'expérience, les programmeurs ne sont plus des « codeurs » qui veillent tard pour écrire des bogues, puis veillent tard pour corriger des bogues, mais les « exécuteurs » d'origine deviennent des « pilotes ».
Il ne s’agit pas seulement d’une « révolution de la productivité » avec une efficacité multipliée par 10, mais aussi d’une subversion de la définition du « génie logiciel » et déclare directement la fin de « l’ère du codage manuel » de l’humanité.
Changement
Commencez avec un dépôt git vide
Cette expérience a commencé avec la première soumission de l'IA.
Fin août 2025, lorsque le premier commit est tombé dans l’entrepôt vide, il n’était plus écrit par des humains – il n’existait aucun code humain existant pouvant servir de « point d’ancrage ».
Encore plus magique : même la première version du manuel d'instructions AGENTS.md utilisé pour guider l'IA dans son fonctionnement a été écrite par l'IA elle-même.
Dès le premier jour, cet entrepôt a été façonné par des agents.Les humains ne sont pas autorisés à écrire du code, ce qui est devenu une règle de fer insurmontable pour ce projet.
Il ne s’agit pas ici de paresse, mais d’une sorte de « pratique délibérée » presque masochiste. Ce n'est qu'en coupant la voie de sortie permettant aux humains de « démarrer » que l'équipe pourra être obligée de résoudre le problème ultime du code du bâtiment sans personne du tout.
En conséquence, cette petite équipe de 3 personnes (plus tard élargie à 7 personnes) a soudainement semblé être un berger tenant un fouet, poussant un groupe d'agents infatigables du Codex à courir sauvagement dans la prairie du code.
Les résultats sont époustouflants :5 mois, 1 million de lignes de code.
Redéfinir le rôle de l'ingénieur
Les premiers progrès de l’expérience ont été plus lents que prévu par les chercheurs d’OpenAI.
Ce n’est pas que le Codex ne fonctionne pas, c’est que l’environnement n’est pas suffisamment clairement défini : l’agent ne dispose pas des outils, des abstractions et des structures internes nécessaires pour atteindre des objectifs de haut niveau.
En conséquence, la tâche principale de l’équipe d’ingénierie d’OpenAI est devenue une seule chose :Donnez à l’agent la possibilité d’effectuer un travail précieux.
Ils divisent les grands objectifs en blocs de construction plus petits (conception, code, révision, test, etc.), invitent l'agent à rassembler ces blocs, puis les utilisent pour débloquer des tâches plus complexes.
Lorsque les choses échouent, la réponse est presque jamais « réessayer ». La seule façon d’avancer est de laisser le Codex faire le travail. Les ingénieurs humains prennent généralement du recul et se demandent :
Quelle capacité manque ? Comment le rendre à la fois visible pour l’agent et exécutoire ?
Tout au long du processus, les humains interagissent avec le système presque entièrement par le biais de mots-guides : l'ingénieur décrit la tâche, exécute l'agent et le laisse lancer une PR.
Pour faire avancer le PR, les chercheurs demanderont au Codex d'auto-examiner les modifications localement, de demander des examens supplémentaires des agents locaux et cloud, de répondre aux commentaires des humains ou des agents, puis de répéter en boucle jusqu'à ce que tous les évaluateurs d'agents soient satisfaits.
Au fil du temps, presque tous les travaux de révision ont été déplacés vers une approche « agent contre agent ».
Améliorer la lisibilité des applications
À mesure que le débit du code augmentait, OpenAI a découvert :Le goulot d’étranglement du codage de l’IA devient la capacité d’inspection manuelle de la qualité (AQ).
Le temps et l’attention de l’homme deviennent ainsi de véritables contraintes.
Afin de briser ce goulot d'étranglement, l'approche d'OpenAI consiste à permettre au Codex de lire directement l'interface utilisateur de l'application, les journaux, les indicateurs d'application, etc.
Ils ont intégré le protocole Chrome DevTools dans le runtime de l'agent et développé des compétences en matière de gestion des instantanés, des captures d'écran et de la navigation DOM.
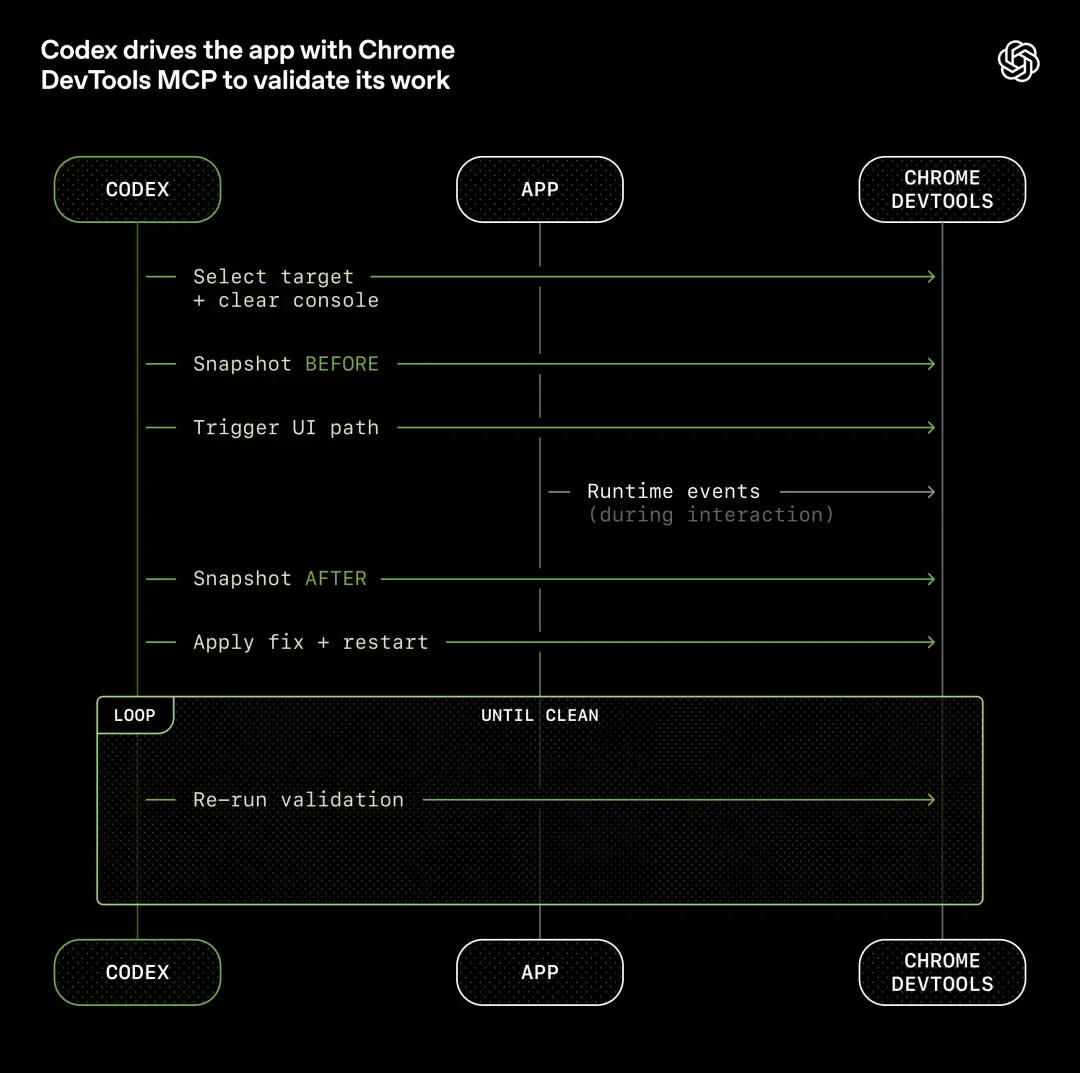
En conséquence, Codex peut reproduire des bogues, vérifier les réparations et raisonner seul sur le comportement de l'interface utilisateur.
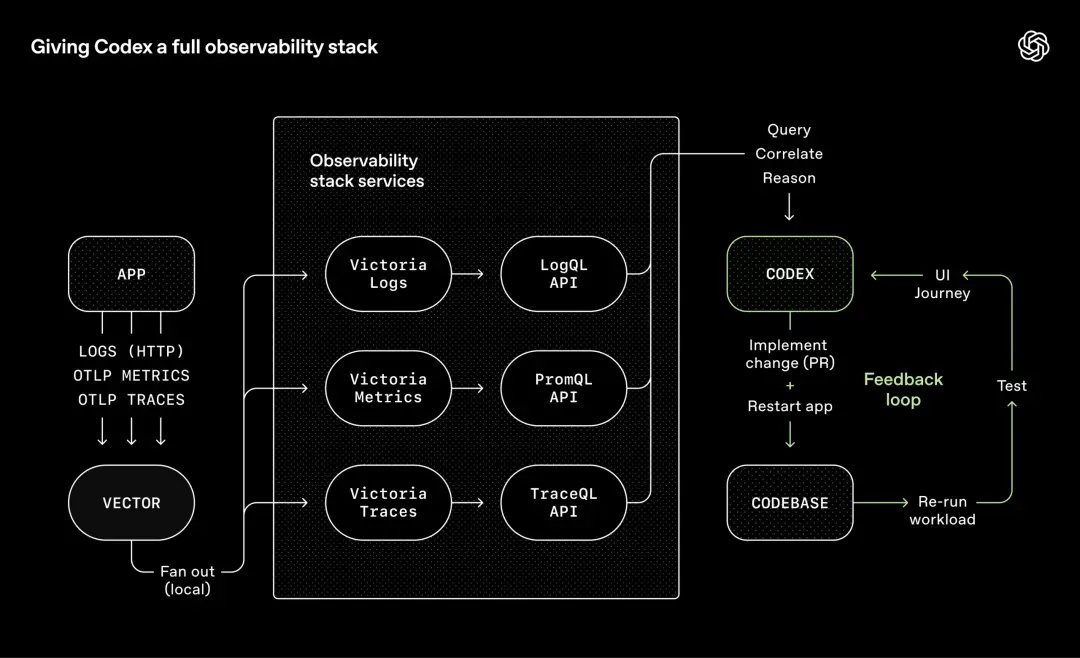
OpenAI adopte la même approche avec les outils d'observabilité.
Les journaux, les métriques et les traces sont exposés au Codex via une pile d'observabilité locale et constituent des environnements isolés et temporaires pour chaque arbre de travail (espace de travail).
Une fois la tâche terminée, l'environnement sera détruit.
Les agents peuvent utiliser LogQ pour vérifier les journaux et PromQL pour vérifier les indicateurs.
En conséquence, des invites telles que « Assurez-vous que le démarrage du service est terminé dans les 800 ms » ou « Aucun écart parmi les quatre chemins d'utilisateur clés ne dépasse deux secondes » deviennent véritablement exécutables.
Après avoir fait cela, les chercheurs d'OpenAI voient souventLe Codex fonctionne en continu pendant plus de six heures d'affilée, généralement pendant que les humains dorment.
Donnez une carte au Codex
Plutôt qu'un manuel de 1 000 pages
La gestion du contexte est l’un des plus grands défis lorsque l’on laisse les agents gérer des tâches volumineuses et complexes.
Une leçon simple que les chercheurs d’OpenAI ont apprise très tôt est la suivante :
Donnez au Codex une carte, pas un manuel de 1 000 pages.
Au début, l'équipe a essayé d'écrire un très gros fichier AGENTS.md et d'y intégrer toutes les règles, la logique et les précautions. Cela s’est avéré être un désastre.
Parce que l’attention de l’IA est également une ressource rare.
Donnez-lui un manuel d'instructions de 1 000 pages et il se perdra dans les détails, manquera des contraintes clés ou se trompera d'objectifs.
De plus, gérer un document unique d'une telle taille est un cauchemar et deviendra bientôt un « cimetière d'anciennes règles ».
En conséquence, l'équipe a rapidement ajusté sa stratégie et transformé AGENTS.md en une « carte au trésor ».
Ce fichier ne fait qu'environ 100 lignes et ne contient aucune connaissance spécifique, juste une table des matières, comme une carte de navigation qui pointe vers des sources de vérité plus profondes au plus profond de l'entrepôt.
Les documents de conception sont catalogués et indexés, y compris le statut de validation et un ensemble de convictions fondamentales qui définissent les principes de fonctionnement « l'agent d'abord ».
La véritable base de connaissances se trouve dans le répertoire structuré docs/ et constitue la source unique de vérité du système.
Il s'agit d'une « divulgation progressive » : l'agent commence par une entrée petite et stable et apprend où chercher ensuite, plutôt que d'être submergé d'informations dès le début.
Les chercheurs d’OpenAI disposent également d’outils pour appliquer cela.
Vérifiez si la base de connaissances est à jour, réticulée et possède une structure correcte grâce à des tâches spécialisées de lint et de CI.
Les documents d'architecture donnent une vue d'ensemble du partitionnement des domaines et de la superposition des packages. La documentation de qualité note chaque domaine de produit et couche d'architecture et suit en permanence les lacunes.
Afin de garantir que l'IA ne lit pas d'informations obsolètes, l'équipe a même spécialement désigné un agent « jardinier de documents ».
Il n'a qu'une seule tâche : analyser régulièrement les documents, rechercher les descriptions obsolètes qui ne correspondent pas à l'implémentation du code, puis lancer automatiquement un correctif PR.
Laissez l’agent intelligent « comprendre »
L’entrepôt étant entièrement généré par l’agent, l’un des objectifs des chercheurs d’OpenAI est de permettre à l’agent de comprendre l’ensemble du domaine métier uniquement en s’appuyant sur l’entrepôt lui-même.
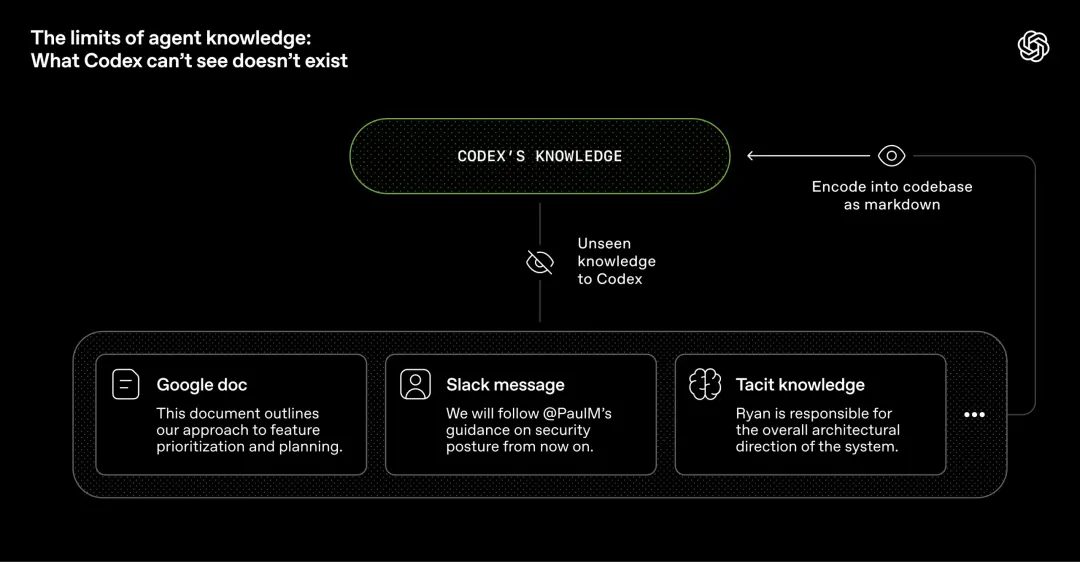
Du point de vue d'un agent, toute connaissance à laquelle il ne peut pas accéder dans le contexte d'exécution n'existe pas.
Par exemple, les connaissances placées dans Google Docs, les enregistrements de discussions et les cerveaux humains sont tous invisibles pour le système.
Tout ce qu'il peut voir, ce sont les artefacts versionnés dans l'entrepôt, tels que le code, le Markdown, le schéma et les plans exécutables.
Si les agents ne parviennent pas à trouver ces connaissances contextuelles, ils seront aussi désemparés que leurs nouveaux collègues de travail et n’auront aucune idée de ce qui se passe réellement dans l’entreprise.
Par conséquent, de plus en plus de contexte doit être repoussé vers l’entrepôt.
Bien entendu, donner plus de contexte au Codex ne signifie pas lui donner des instructions plus éparses, mais organiser et structurer l’information de manière à ce qu’elle puisse être raisonnée.
Clôture automatisée
Laissez les programmeurs devenir les « bergers » du monde du code
La documentation à elle seule ne suffit pas à rendre cohérente une base de code entièrement générée par un agent.
Après tout, l’IA est un modèle probabiliste. Il peut halluciner, être paresseux et écrire du code qui « semble fonctionner mais qui est en réalité un gâchis ».
Comment le résoudre ?
Les agents fonctionnent mieux dans des environnements dotés de limites claires et de structures prévisibles.
En appliquant des « invariants » plutôt qu'en gérant les détails de la mise en œuvre, OpenAI permet aux agents d'avancer à grande vitesse sans briser les fondations.
C'est comme mettre les rênes et la selle d'un cheval IA comme Codex qui parcourt des milliers de kilomètres chaque jour.
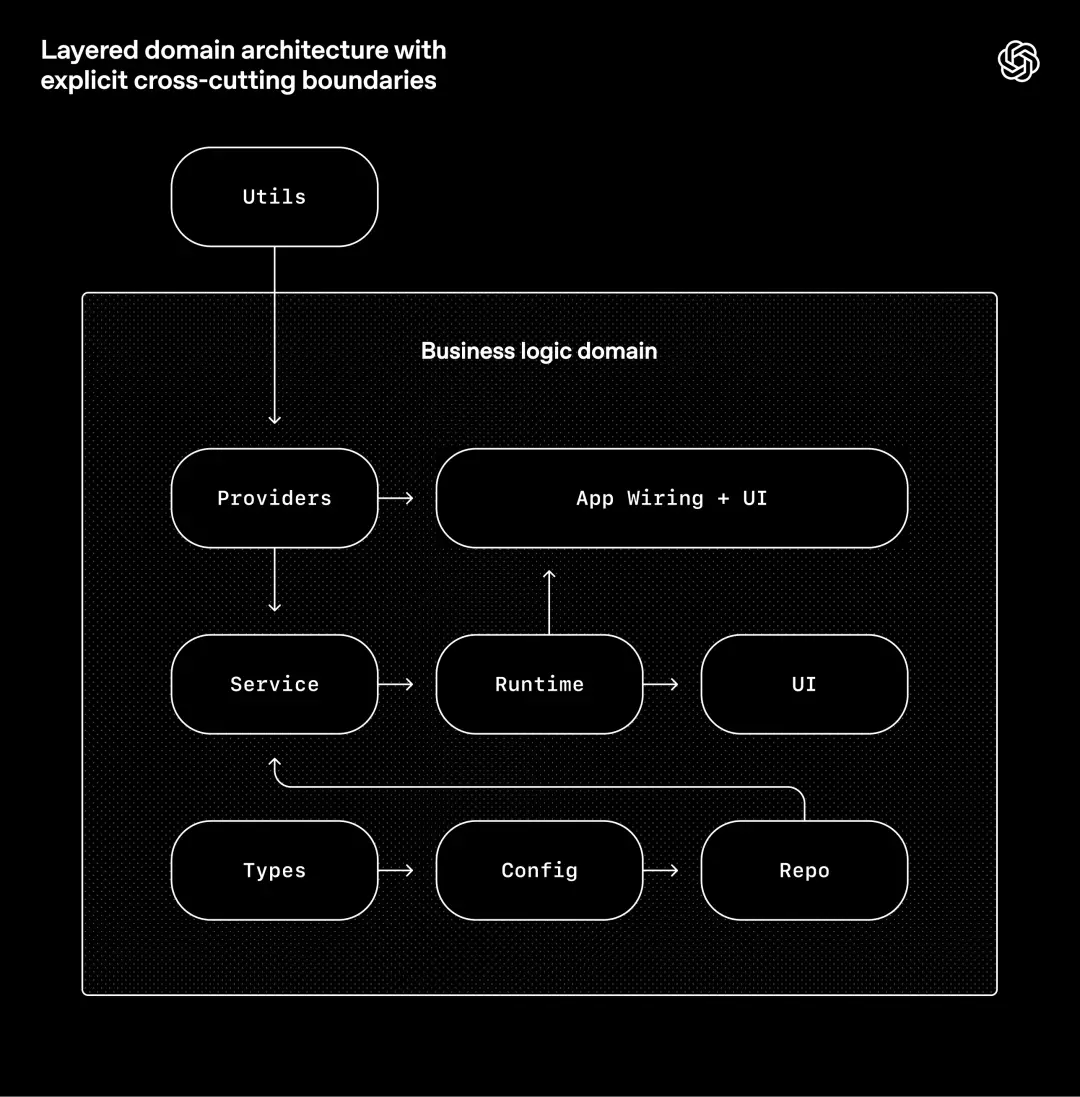
OpenAI construit des systèmes autour d'un modèle architectural rigoureux. Chaque domaine d'activité a une hiérarchie fixe et les directions de dépendance sont strictement vérifiées, n'autorisant que des limites juridiques limitées.
La règle est simple : au sein de chaque domaine d'activité (comme les paramètres de l'application), le code ne peut dépendre que du « forward » le long d'une hiérarchie fixe :
Types → Configuration → Repo → Service → Runtime → UI
Les préoccupations transversales (authentification, connecteurs, télémétrie, commutateurs de fonctionnalités, etc.) ne sont disponibles que via une seule interface explicite : les fournisseurs.
D'autres dépendances sont interdites et appliquées via des peluches personnalisées (également générées par le Codex) et des tests structurels.
Ce type d’architecture n’est généralement soigneusement conçu que lorsque l’échelle de l’entreprise atteint des centaines de personnes.Mais dans le cas des agents codants, c’est une condition préalable.
De plus, les chercheurs d’OpenAI ont défini un ensemble d’« invariants gustatifs » tels que :
Forcer la journalisation structurée
Conventions de dénomination des schémas et des types
Taille maximale du fichier
Exigences de fiabilité au niveau de la plate-forme
Dans ce processus, une distinction claire doit être faite entre les domaines dans lesquels la rigueur est requise et les domaines dans lesquels l'autorité peut être déléguée.
C'est comme gérer une grande plateforme d'ingénierie : un contrôle centralisé aux frontières et un haut degré d'autonomie interne.
Le code généré par l’IA n’est peut-être pas conforme à l’esthétique humaine, mais tant qu’il est correct, maintenable et lisible par l’agent intelligent, tout va bien.
Dans ce processus, le goût humain ne disparaîtra pas, mais continuera à être « codé » dans le système.
Les commentaires de révision, la refactorisation des PR et les bogues des utilisateurs seront convertis en mises à jour de documents ou directement mis à niveau vers les règles de l'outil.
Lorsque la documentation ne suffit pas, les règles doivent être écrites dans le code.
Jetez le clavier
Soyez courageux pour contrôler l'IA
Cette expérience d'OpenAI a annoncé :Un grand nombre d’emplois basés sur CRUD sont en train d’être remodelés.
Si un système parti de zéro peut être construit à l'échelle d'un million de lignes par trois personnes (sans écrire une seule ligne de code) en 5 mois, est-il encore nécessaire que les énormes équipes de développement des éditeurs de logiciels traditionnels existent ?
Dans cette nouvelle ère à venir, la définition d’un ingénieur sera complètement réécrite.
Ce dont vous avez besoin, ce sont de solides « capacités architecturales » pour pouvoir définir les limites du système, concevoir les contraintes entre les modules et construire la « clôture » qui empêche l’IA de s’égarer.
Dans le même temps, vous avez également besoin de « compétences d’expression » précises et apprenez à décrire vos intentions à l’IA dans le langage le plus clair (qu’il s’agisse d’un langage naturel ou de documents structurés).
Ceux qui refusent la programmation de l’IA et insistent sur le codage manuel finiront par être engloutis par la vague. Seuls les programmeurs qui savent contrôler l'IA sont susceptibles de devenir des gagnants à l'ère de l'IA.