NVIDIA a annoncé,DGX Spark a introduit de nouvelles fonctionnalités et prend désormais en charge la mise en réseau en cluster de jusqu'à 4 appareils pour créer un « centre de données de bureau » compact.Surnommé « Little Golden Box » par tout le monde, un seul DGX Spark possède une puissance de calcul IA de 1 quadrillion de fois par seconde et est associé à 128 Go de mémoire unifiée LPDDR5X.Quatre unités en parallèle disposent de 4 pétaflops de puissance de calcul et de 512 Go de mémoire unifiée.

DGX Spark prend désormais en charge une variété de topologies d'exploitation, toutes reposant sur la communication RoCE à faible latence fournie par la carte réseau ConnectX-7 et spécialement optimisée pour différents objectifs :
Nœud unique :
Convient au raisonnement à faible latence et à grande longueur de contexte,Peut déduire des modèles comportant jusqu'à 200 milliards de paramètres et affiner des modèles comportant jusqu'à 120 milliards de paramètres., ainsi que les charges de travail de type agent local.
Nœuds doubles :
Une extension équilibrée peut effectuer un réglage précis plus rapidement et prendre en charge des modèles plus grands.Il peut prendre en charge le raisonnement de modèles comportant jusqu’à 400 milliards de paramètres.
Trois nœuds (topologie en anneau) :
Convient pour le réglage fin de modèles plus grands ou les petites tâches de formation.
Quatre nœuds (avec commutateur RoCE 200GbE) :
Peut être utilisé comme serveur d'inférence local,Prend parfaitement en charge les grands modèles de pointe avec jusqu'à 700 milliards de paramètres, les charges de travail gourmandes en communication et les opérations d'usine d'IA locale.

NVIDIA affirme que,Plusieurs serveurs DGX Spark peuvent être utilisés en parallèle pour obtenir une expansion des performances quasi linéaire et ne nécessitent pas de configurations complexes comme les déploiements de serveurs traditionnels montés en rack.
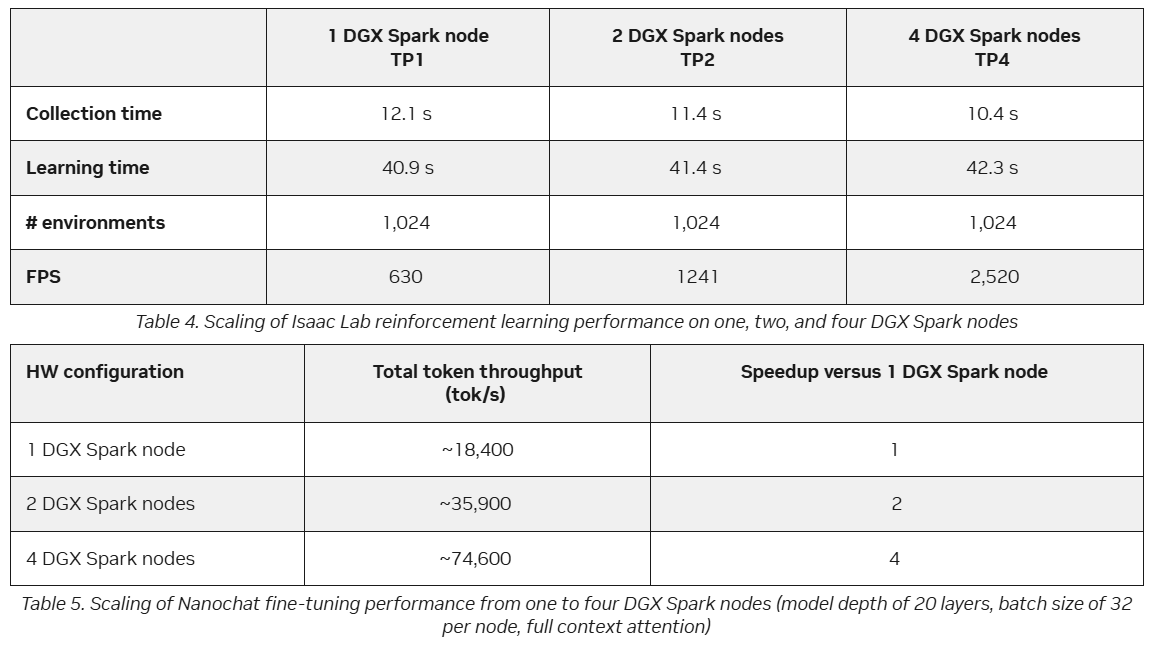
Par exemple, les performances de l'apprentissage par renforcement d'Isaac Lab sont de 630 FPS pour un seul nœud, doublées à 1 241 FPS pour deux nœuds et doublées à nouveau à 2 520 FPS pour quatre nœuds, tandis que la latence reste pratiquement inchangée.
Un autre exemple est la performance du réglage fin de Nanochat. La vitesse de sortie du jeton à nœud unique est d'environ 18 400 par seconde, la vitesse de sortie du jeton à double nœud double pour atteindre 35 900 et la vitesse de sortie du jeton à quatre nœuds double à nouveau pour atteindre 74 600.
Dans le même temps, NVIDIA a également lancéLa nouvelle pile technologique open source NVIDIA NemoClaw, DGX Spark peut fournir une plate-forme complète qui prend en charge la construction et l'exploitation locales d'agents d'IA autonomes à long terme, et peut ensuite être étendue de manière transparente aux infrastructures de centres de données telles que les usines d'IA.
Par ailleurs, DGX Spark inaugurera bientôtnouvelle version du logiciel, qui peut encore améliorer les capacités d'orchestration et de gestion et accélérer l'itération du prototype à la production.
À l'heure actuelle, de nombreuses organisations industrielles telles que la finance, les soins médicaux, l'énergie, les communications, etc. ont déployé DGX Spark.

On peut dire que cette mise à niveau majeure du DGX Spark démontre une fois de plus le double leadership de NVIDIA en matière d’architecture matérielle d’IA et d’écosystème technologique.
Du déploiement d'un appareil unique au déploiement en cluster, du développement local à la mise en œuvre au niveau de l'entreprise, NVIDIA a une fois de plus défini une nouvelle référence pour l'infrastructure d'IA au niveau des ordinateurs de bureau avec sa technologie de pointe et sa disposition avant-gardiste, consolidant ainsi son leadership absolu dans le domaine de la puissance de calcul mondiale de l'IA.
De deux nœuds à quatre nœuds, les utilisateurs d'entreprise pourront à l'avenir utiliser plus efficacement les avantages de la puissance de calcul de DGX Spark pour parvenir à une mise en œuvre rapide des services d'IA et promouvoir la mise en œuvre généralisée des agents d'IA.
