Le 27 juin, DeepSeek a publié le rapport technique DSpark et la base de code DeepSpec. Le modèle de base de DeepSeek-V4 n'a pas changé. La nouveauté est un module de décodage spéculatif côté serveur : DSpark. DeepSeek le dit très crûment sur la page du modèle HuggingFace : V4-Pro-DSpark et V4-Flash-DSpark ne sont « pas de nouveaux modèles ». Ces deux pages pointent vers le même point de contrôle du modèle, plus la version du service après avoir spéculé sur le module décodé.

Cela signifie que DSpark ne rend pas le modèle soudainement plus intelligent. Il vise à déterminer comment fournir des réponses plus rapidement et à moindre coût une fois le modèle mis en ligne.
Le rapport technique indique que DSpark a été déployé dans le système de service en ligne de DeepSeek-V4. Dans le cadre d'un trafic utilisateur réel, par rapport à la référence de production précédente MTP-1, qui est la solution de génération de spéculation en ligne de génération précédente de DeepSeek, la vitesse de génération par utilisateur de V4-Flash est augmentée de 60 % à 85 %, et celle de V4-Pro est augmentée de 57 % à 78 %, à condition que les conditions de débit soient respectées.
Le « jeûne » ici doit également être tempéré.Il fait principalement référence à l'étape de génération, c'est-à-dire à la vitesse à laquelle le modèle continue de produire des jetons. Cela ne signifie pas que le temps de réponse de bout en bout de toutes les demandes des utilisateurs est 85 % plus rapide.Le pré-remplissage de longs mots d'invite, la récupération, l'appel d'outils, la mise en file d'attente et les retards du réseau affecteront toujours la durée d'attente réelle des utilisateurs.
Une fois le modèle en ligne, il existe toujours un compte d'inférence
Cette chose n’est pas aussi vivante qu’une sortie de nouveau modèle, mais elle est plus proche de la réalité à laquelle les entreprises d’IA sont confrontées chaque jour :Le coût ne s’arrête pas une fois le modèle formé.
Les chatbots, les assistants de code, les agents et les produits basés sur la recherche continuent de consommer du temps GPU à chaque appel. Si le modèle est plus lent, les utilisateurs devront attendre plus longtemps ; si l’inférence coûte plus cher, il sera plus difficile pour les fabricants d’ouvrir des modèles de haute qualité à davantage de scénarios.
L'industrie de l'IA est devenue plus habituée à discuter des coûts de formation au cours des deux dernières années : combien de GPU une entreprise doit acheter, quelle taille de cluster elle devrait construire et combien il en coûtera pour former le modèle de nouvelle génération. Mais une fois que le modèle est devenu un produit, un autre type de coût continuera à apparaître : l’inférence.
La formation est comme un grand projet et le raisonnement est comme une facture de services publics.Tant que les utilisateurs posent des questions, que les agents exécutent des tâches et que les assistants de code génèrent des correctifs, le modèle continuera à consommer de la puissance de calcul.
Les services de grand modèle reviendront à terme à deux indicateurs : la vitesse et le coût unitaire du jeton. Les pages de tarification des API facturent généralement en fonction des jetons d'entrée et des jetons de sortie, et les entreprises divisent également différents modèles, caches, itinéraires et longueurs de contexte en éléments de coût en interne.
DSpark ne peut pas être directement assimilé à une réduction de prix, mais si le même cluster GPU peut permettre aux utilisateurs d'obtenir des réponses plus rapidement avec un débit similaire, cela signifie que le même matériel peut servir plus d'utilisateurs, ou que la même expérience utilisateur peut être fournie avec moins de cartes.
"Devinez d'abord, puis testez"
L'idée du décodage spéculatif peut être grossièrement comprise comme « devinez d'abord, puis testez ».
Lorsqu'un grand modèle génère du texte, il crache généralement jeton après jeton. Une fois le jeton précédent sorti, le jeton suivant saura quoi récupérer. Cette méthode est stable mais lente. Le décodage spéculatif permettra à un module de brouillon plus léger de deviner un jeton candidat à l'avance, et le grand modèle cible sera vérifié par lots. La bonne supposition est acceptée directement et la supposition incorrecte est corrigée.
Les petits modèles ne peuvent pas prendre de décisions à la place des grands modèles. Les jetons finalement acceptés sont toujours vérifiés par le modèle cible ; lorsqu'il est implémenté correctement, il modifie la méthode de génération et ne modifie pas la distribution de sortie du modèle cible.L'accélération vient du fait que de grands modèles valident les candidats par lots, plutôt que progressivement.
Ce que DSpark a changé, c'est comment générer un brouillon
L'article ne s'arrête pas à l'explication « devinez d'abord, puis testez ». Il se concentre sur la façon de générer des brouillons.

Les projets de stratégies existants se répartissent globalement en deux catégories. Le rédacteur autorégressif est plus stable car le dernier jeton verra le jeton précédent, mais à mesure que le brouillon s'allonge, le délai augmentera également. Le rédacteur parallèle est plus rapide et peut deviner un paragraphe entier à la fois, mais chaque position est devinée séparément. Les derniers jetons sont facilement déconnectés des précédents et le taux d'acceptation est plus susceptible de diminuer au fur et à mesure qu'il avance.
DSpark choisit de faire des compromis.Le mot clé dans le titre de l'article est « Génération semi-autorégressive ». Il utilise d'abord une méthode parallèle pour proposer un candidat, puis utilise une couche séquentielle légère pour modifier la relation conditionnelle des jetons suivants. Cela permet non seulement de conserver la vitesse de génération parallèle, mais permet également aux candidats suivants de voir ce qui a été deviné précédemment.

Un autre point clé est la durée de la vérification.
Plus vous devinez de jetons candidats, moins vous économisez. Si vous savez que la seconde moitié est susceptible d'être rejetée et que vous la confiez néanmoins à un grand modèle pour vérification, vous passez du temps GPU sur une position de faible valeur.DSpark examinera la confiance du candidat et la charge actuelle du système pour déterminer dynamiquement la longueur de la vérification.Si le GPU est vide, vous pouvez effectuer plusieurs tests ; lorsque la charge est élevée, la puissance de calcul est réservée aux parties les plus susceptibles d'être acceptées.
C’est de cela dont parle le « Confiance-Scheduled » dans le titre du journal.

DSpark se situe sur les itinéraires techniques existants
DSpark s'appuie sur des spéculations sur la voie de décodage existante et ressemble davantage à une référence publique après que DeepSeek ait poussé cette voie technique vers les services en ligne.
SpecInfer a intégré la prédiction de petits modèles, l'arbre de jetons et la vérification parallèle dans le système de services de grands modèles dès 2023 ; Medusa a proposé d'ajouter plusieurs têtes de décodage au modèle en 2024 pour prédire plusieurs jetons suivants à la fois ; la série EAGLE continue d'améliorer le taux d'acceptation des modèles de brouillon et des arbres de brouillon dynamiques. Les frameworks d'inférence tels que vLLM, SGLang et TensorRT-LLM considèrent depuis longtemps le décodage spéculatif comme un outil important pour réduire la latence.
L'avantage de DSpark est qu'il gère plusieurs problèmes de production ensemble : comment générer des brouillons, comment maintenir la cohérence des candidats, comment la longueur de vérification change avec la charge et dans quelle mesure la vitesse peut être améliorée dans un trafic en ligne réel.
Les mots clés qui apparaissent à plusieurs reprises dans le document sont également passés de « amélioration des capacités du modèle » à des termes liés au service, tels que vitesse de génération par utilisateur, débit adapté et accord de niveau de service (SLA).
Cela explique également pourquoi vous ne pouvez pas simplement choisir le plus grand nombre à examiner. Il existe effectivement des données à haut débit telles que 661 % et 406 % dans le document, mais elles proviennent d'objectifs de vitesse par utilisateur plus stricts : avec ce paramètre, l'ancienne ligne de base elle-même est déjà proche de la limite des capacités de service, et l'avantage relatif de DSpark sera amplifié.
Ce qui peut vraiment illustrer les avantages normaux, c'est l'ensemble de chiffres précédent : débit correspondant, répartition réelle du trafic, et l'objet de comparaison est MTP-1.
Que peut reproduire DeepSpec ?
DeepSeek ouvre également DeepSpec en open source. Il s'agit d'une bibliothèque de codes permettant de former et d'évaluer des projets de modèles de décodage spéculatif. Il comprend des processus de préparation des données, de formation et d'évaluation, et publie également des points de contrôle pertinents sur Qwen3, Gemma et d'autres modèles.
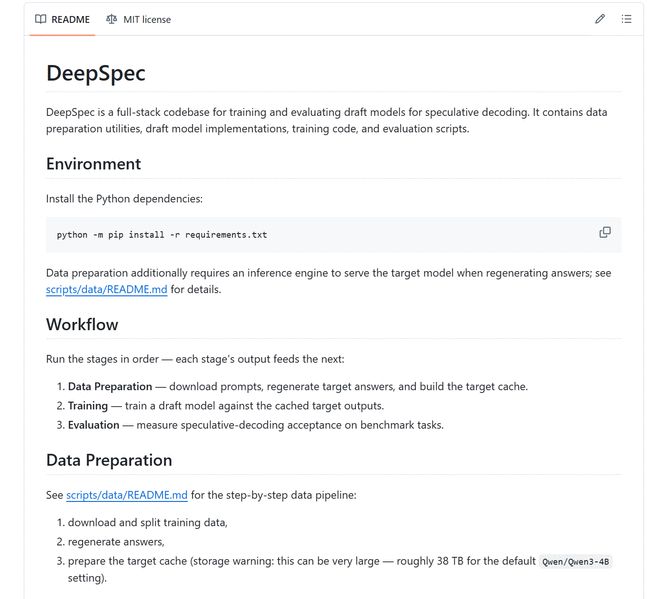
mais,Open source ne signifie pas « télécharger et reproduire ».La documentation du projet indique que dans la configuration par défaut de Qwen3-4B, le cache du modèle cible peut être proche de 38 To ; le script de formation par défaut suppose 8 GPU sur un seul nœud ; si les résultats papier doivent être alignés, les paramètres de formation doivent être strictement cohérents et des ajustements supplémentaires du projet de modèle sont nécessaires dans des domaines spécifiques.
Le monde extérieur peut vérifier une partie de la méthode et peut également transplanter DeepSpec sur d'autres modèles open source, mais l'ensemble des chiffres d'amélioration de la vitesse dans le service en ligne DeepSeek-V4 provient toujours de l'échelle matérielle, de la répartition du trafic et de la planification du système de production de DeepSeek.
L'Open Source est la méthode, pas l'environnement.
La communauté est la plus préoccupée par les frontières récurrentes
La discussion sur
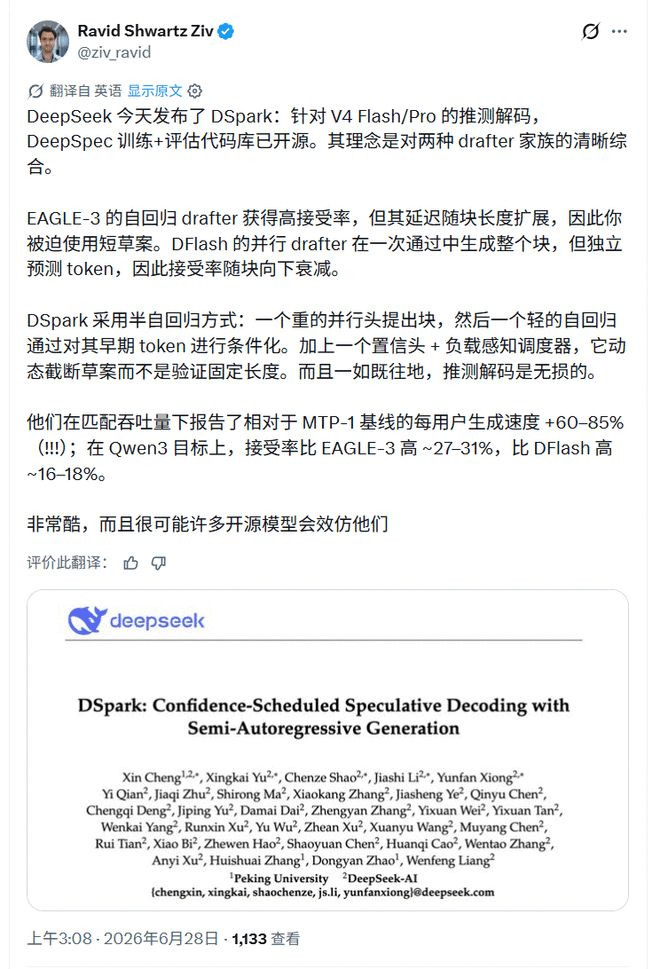
Le chercheur en IA Ravid ShwartzZiv résume DSpark comme un compromis entre deux types de rédacteurs : le rédacteur parallèle est rapide, mais le taux d'acceptation décroît le long du bloc candidat ; le rédacteur autorégressif est stable, mais le délai augmente avec la longueur du projet. Il a spécifiquement mentionné deux composants ajoutés à DSpark : la tête de jugement de confiance et le planificateur sensible à la charge, et a ajouté une limite clé : « Comme tout décodage spéculatif, il est sans perte. »
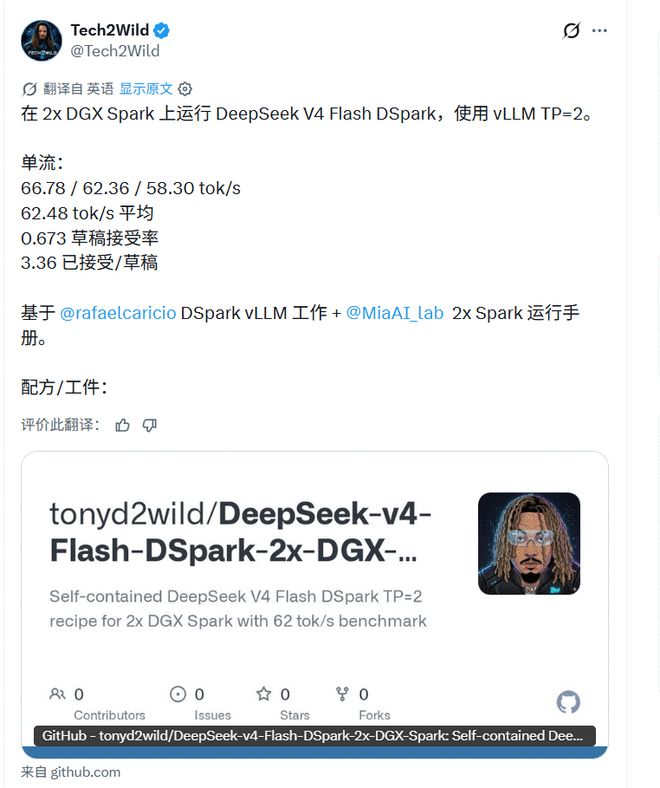
Les ingénieurs se soucient davantage de savoir s’il peut fonctionner. Rafael Caricio, contributeur de vLLM, a déclaré qu'il avait exécuté le mode DSpark de DeepSeek-V4-Flash sur le double DGX Spark GB10 et que le décodage à flux unique était d'environ 60 tok/s, soit environ 1,5 fois celui de MTP-1.
Il a également mentionné que la session de code réelle a révélé des problèmes que les benchmarks synthétiques ne pouvaient pas voir : le goulot d'étranglement n'est pas seulement la vitesse du cœur de calcul, mais le taux d'acceptation des projets diminuera considérablement dans un contexte long.
Tech2Wild a également fourni des données sur site dans une direction similaire, montrant que V4-Flash-DSpark a été testé dans un environnement vLLM spécifique. Cependant, ces résultats dépendent fortement du modèle matériel, de la version du correctif du framework, de la longueur du contexte et des paramètres de concurrence. Les résultats peuvent être complètement différents dans un autre environnement.
Il y a aussi des gens qui rappellent spécifiquement les limites. AcingAI souligné sur
Cela nous rappelle qu'une partie de l'avantage de DSpark vient de la planification sensible à la charge, et l'effet de planification dépend naturellement de l'échelle du trafic et de la configuration matérielle de l'environnement de production.
Même puissance, moins de puissance de calcul
Dans un rapport du 28 juin, le South China Morning Post a examiné DSpark en termes de goulots d'étranglement d'inférence, de pression sur les puces et de temps d'attente des utilisateurs. Cette perspective est plus proche de la réalité du produit que « Quel modèle DeepSeek a-t-il encore publié ? »
Les entreprises d’IA continueront de comparer les capacités des modèles, mais lorsque l’écart de capacités sera réduit, celui qui peut fournir les mêmes capacités plus rapidement et à moindre coût fera également partie de la concurrence.
Des entreprises comme DeepSeek doivent particulièrement le préciser. DeepSeek a toujours considéré le faible coût et la haute efficacité comme un point d'entrée important pour permettre au monde extérieur de le comprendre. Du récit de formation du modèle au prix de l'API, ce qui attire le plus l'attention n'est pas de savoir si elle a une plus grande échelle de paramètres, mais si elle peut rendre les mêmes capacités moins chères.
DSpark continue sur cette lancée : cela ne prouve pas que la V4 est soudainement plus intelligente, cela prouve que la V4 peut gaspiller moins de puissance de calcul en raisonnant au service des utilisateurs.
Si nous élargissons un peu plus notre perspective, l’optimisation de l’inférence affectera également l’écologie des modèles open source. Le modèle open source était autrefois considéré comme « bon marché », mais lorsqu'il sera effectivement déployé, la mémoire graphique, le débit, la simultanéité, la latence et la complexité d'exploitation et de maintenance deviendront tous des coûts.
Si un modèle peut être open source, cela signifie simplement que tout le monde peut l’obtenir ; sa capacité à servir un grand nombre d'utilisateurs à moindre coût dépend de la capacité de la pile d'inférence à suivre le rythme.
DeepSpec a publié Qwen3, Gemma et d'autres points de contrôle, indiquant que cette affaire ne s'arrête pas à DeepSeek-V4 lui-même. L'ampleur de la migration dépend des progrès réels de l'adaptation de la communauté, du support du framework et de la compatibilité matérielle ; mais à en juger par les informations publiques actuelles, DeepSeek a emprunté cette voie en dehors de son propre modèle.
La valeur de DSpark réside ici.Il ajoute à la V4 une couche d'outils de service d'inférence plus proche du système de production, plutôt qu'une simple nouvelle étiquette de capacité.
Ce qui mérite d’être observé ensuite, ce n’est pas seulement la vitesse à laquelle DeepSeek peut fonctionner, mais aussi le nombre de personnes qui peuvent emprunter cette route. DeepSpec a publié des points de contrôle et des processus de formation, et on suppose que le décodage est en train de passer du choix d'ingénierie d'une entreprise à un moyen courant d'inférence open source pour réduire les coûts.Cela suppose que d’autres frameworks et matériels puissent suivre le rythme.