Lors de la conférence Cloud Next de la semaine dernière, Google a annoncé que le modèle Gemini 2.5 Flash arriverait bientôt et apporterait des améliorations significatives. Aujourd'hui, Google a annoncé l'aperçu Gemini 2.5 Flash dans l'API Gemini via Google AI Studio et Vertex AI. Ce nouveau modèle est également disponible pour les utilisateurs de Gemini via le sélecteur de modèle et fonctionne avec Canvas pour optimiser facilement les documents et le code.

Suite à la génération précédente Gemini 2.0 Flash, Gemini 2.5 Flash a considérablement amélioré les capacités d'inférence tout en réduisant les coûts et la latence. Google affirme que ce nouveau modèle présente un excellent rapport qualité-prix. Les tarifs spécifiques sont les suivants :
0,15 $ pour 1 million de jetons d'entrée
pour 1 million de produitsélément de motFacturer 0,60 $ (aucun raisonnement requis)
3,50 $ pour 1 million de jetons de sortie (y compris l'inférence)
Il s'agit d'une première version de Flash 2.5, mais elle présente déjà d'énormes améliorations de performances par rapport à la version Flash 2.0.
Si vous le souhaitez, vous pouvez désactiver complètement la fonction de réflexion et utiliser ce modèle en remplacement de Flash 2.0.
Il est disponible dans les applications Gemini API, AI Studio, Vertex et Gemini !
–Logan Kilpatrick (@OfficialLoganK)
Gemini 2.5 Flash est le premier modèle d'inférence entièrement hybride de Google, permettant aux développeurs de choisir d'activer ou de désactiver l'inférence. Cela aiderait les développeurs à optimiser les réponses en fonction de la qualité cible, du coût et de la latence. Découvrez les références de ce nouveau modèle ci-dessous.
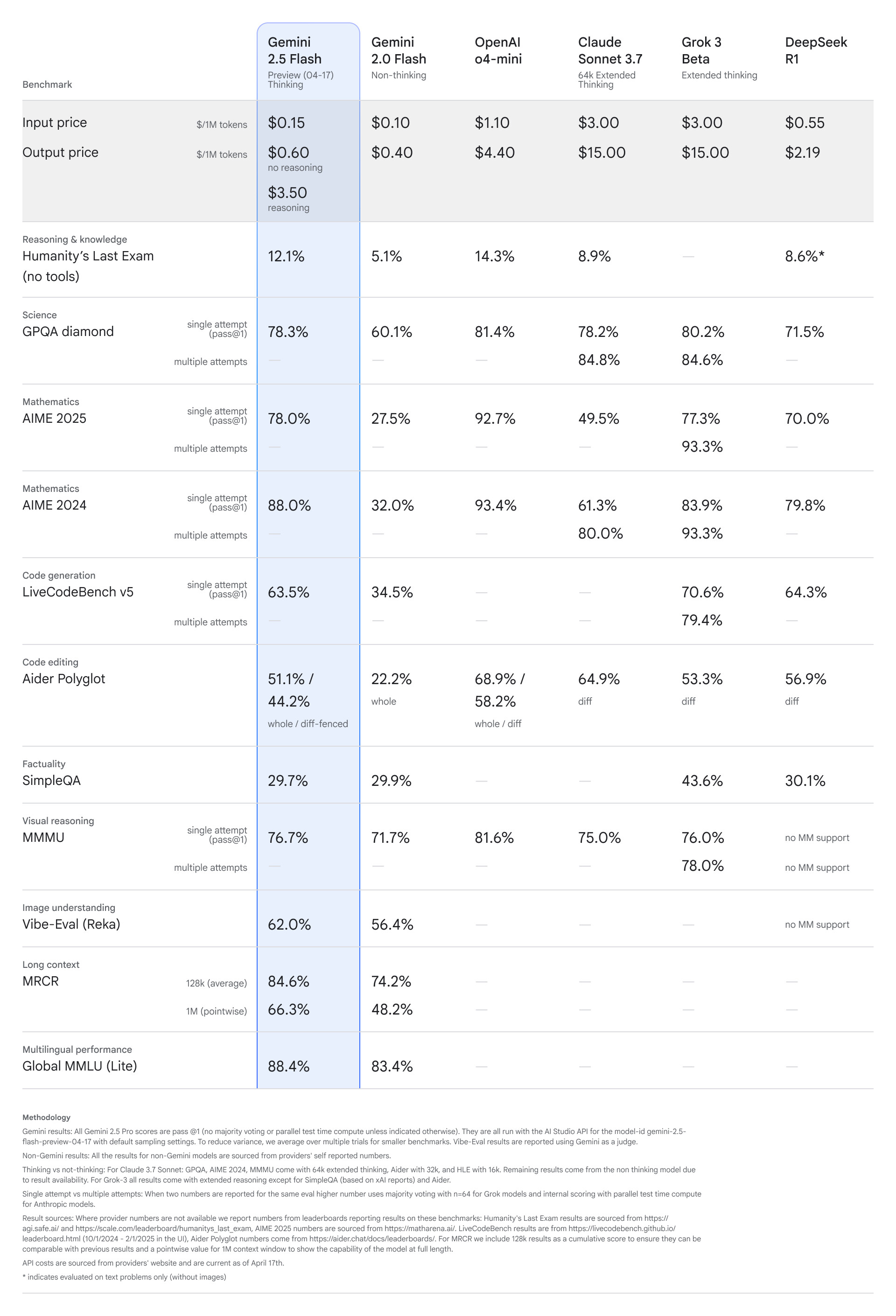
Comme le montre le tableau ci-dessus, malgré son faible coût, le Gemini 2.5 Flash semble toujours tenir tête aux modèles pointus d'Anthropic et Grok. Le o4-mini récemment publié par OpenAI semble fonctionner mieux que l'aperçu Flash de Gemini 2.5, mais le prix est beaucoup plus élevé.