La version préliminaire de DeepSeek-V4 est enfin disponible. Aujourd'hui, DeepSeek a officiellement annoncé que deux modèles, deepseek-v4-pro et deepseek-v4-flash, avec un contexte ultra-long d'un million de mots, ont été publiés et open source. À partir de maintenant, vous pouvez vous connecter au site officiel ou à l'application officielle pour parler du dernier DeepSeek-V4 et explorer la nouvelle expérience de 1 million (million) de mémoire contextuelle ultra longue. Le service API a été mis à jour simultanément.

Article 丨 Colonne "BUG" Zhou Wenmeng

Selon le test de référence officiel, en termes de longueur de contexte, de connaissances, de raisonnement et de capacités de l'agent, DeepSeek Les performances de la V4 sont comparables à celles des meilleurs modèles internationaux à code source fermé. et a atteint le niveau de premier ordre des modèles open source internationaux. Une comparaison dans la colonne « BUG » a révélé qu'en termes de prix d'appel API, la version V4 de DeepSeek, qui à elle seule a entraîné des baisses de prix dans l'industrie nationale des grands modèles l'année dernière, a une fois de plus fixé le « prix le plus bas » de l'industrie.
"Bien que le prix d'appel par million de jetons des modèles nationaux n'ait pas beaucoup baissé, la longue durée du contexte et les bonnes performances lui confèrent un avantage très compétitif !" Certains initiés ont exprimé leurs sentiments lors de la communication avec la colonne "BUG" Regret : "Ce boucher à gros prix de modèle est de retour !"Selon l'introduction officielle de DeepSeek, la série V4 comprend deux versions du modèle : DeepSeek-V4-Pro avec 1,6T de paramètres totaux, 49B de paramètres d'activation et 33T de données de pré-entraînement ; DeepSeek-V4-Flash avec 284 B de paramètres au total, 13 B de paramètres d'activation et 32 T de données de pré-entraînement ; les deux prennent en charge nativement 1 million de contextes de jetons.
Selon les données de test de référence divulguées par DeepSeek, dans les tests de connaissances et de raisonnement, DeepSeek-V4-Pro-Max a obtenu les meilleures performances dans les tests Apex Shortlist et Codeforces, surpassant Claude-Opus-4.6-Max, GPT-5.4-xHigh, Gemin-3.1-Pro-Hight et d'autres modèles internationaux, démontrant des capacités logiques et algorithmiques extrêmement fortes ; dans SimpleQA Dans le test Vérifié, il est légèrement derrière Gemini-3.1-Pro-High mais devant Claude et GPT.
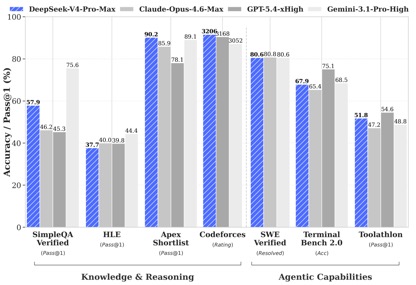
Dans l'évaluation des capacités Agentic, les trois modèles V4, Opus-4.6 et Gemin-3.1-pro étaient à égalité sur la tâche SWE Verified, et DeepSeek a atteint un niveau juste derrière GPT-5.4-xHigh sur la tâche Toolathlon, et sur Terminal Bench 2.0 a atteint un niveau meilleur que Opus-4.6, reflétant ses avantages dans l'enseignement complexe. scénarios d’exécution et d’appel d’outils.
Actuellement, DeepSeek-V4 est devenu le modèle de codage agent utilisé par les employés de l'entreprise. Selon les retours d'évaluation, l'expérience d'utilisation est meilleure que celle de Sonnet 4.5 et la qualité de livraison est proche du mode sans réflexion de l'Opus 4.6.
Dans l'évaluation des codes mathématiques, STEM et compétitifs, DeepSeek-V4-Pro a surpassé la plupart des modèles open source qui ont été évalués publiquement et a obtenu des résultats comparables aux meilleurs modèles fermés au monde.
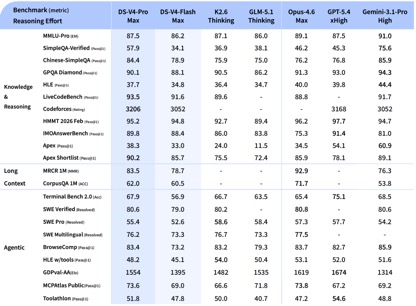
Dans l'ensemble, en termes de capacités de traitement des connaissances et de raisonnement, DeepSeek-v4 a atteint une avance globale sur les modèles open source nationaux et est comparable aux capacités d'évaluation internationales. Cependant, en termes de capacités Agentic, bien que le dernier DeepSeek-v4 ait apporté de bonnes améliorations, l'écart entre les capacités nationales et internationales de premier niveau ne s'est pas creusé, et chacun est en avance.
" Standard" 1 million de contexte, Le boucher Price "est de retour"
Par rapport aux avantages en termes de performances reflétés dans divers tests de référence, la principale caractéristique de cette version V4 est la percée dans les capacités de texte long et la réduction supplémentaire des prix des appels API.
Grâce au nouveau mécanisme d'attention mis au point par DeepSeek-V4, la V4 atteint des capacités de contexte long de pointe en compressant la dimension du jeton et en la combinant avec l'attention sparse DSA (DeepSeek Sparse Attention). Par rapport aux méthodes traditionnelles, cela réduit considérablement les besoins en mémoire informatique et vidéo, faisant de 1 million (un million) de contexte la norme pour tous les services officiels DeepSeek.
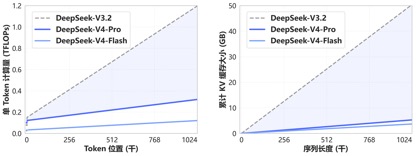
Il y a un an, 1 million de contextes était l'atout exclusif de Gemini. Même dans la plupart des modèles open source nationaux grand public récemment publiés, la longueur des contextes de modèle était principalement comprise entre 128 000 et 200 000. DeepSeek a directement transformé les millions de contextes de « fonctions fermées haut de gamme » en configurations standard open source.
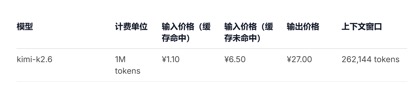
En termes d'appels de prix API, par rapport au prix unitaire d'entrée actuel du GLM-5.1 de 1,3 yuans à 2 yuans/million de jetons (accès au cache) et au Kimi-K2.6 de 1,1 yuans/million de jetons (accès au cache), DeepSeek-v4 -Pour les versions pro et flash, les prix unitaires d'entrée sont respectivement de 1 yuan/million de jetons et de 0,2 yuans/million de jetons. Bien que les prix n'aient pas beaucoup baissé, ils sont tous deux les plus bas et la durée du contexte a été allongée plusieurs fois.
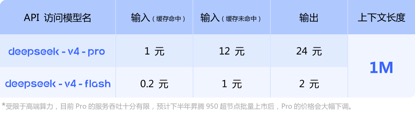
(prix d'appel de l'API du modèle de la série DeepSeek-v4)
[GT20GT ]
(prix d'appel de l'API du modèle Kimi-k2.6)
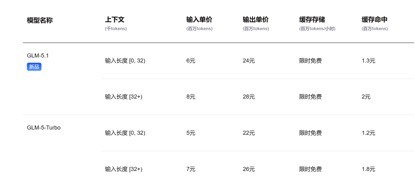
(prix d'appel de l'API du modèle GLM-5.1)
"L'avancée en termes de performances apportée par la sortie de DeepSeek-v4 a moins d'impact que la sortie de DeepSeek-R1. Les performances sont toujours au premier échelon, mais l'avance n'a pas été complètement étendue." De l'avis des initiés de l'industrie, « la sortie du modèle V4 concerne davantage l'amélioration des capacités de texte long et la réduction supplémentaire des prix ».
[ GT1GT] Cette personne a déploré : « Après la version précédente des modèles DeepSeek-V3 et R1, les avantages en termes de performances apportés par l'innovation technologique sous-jacente ont directement favorisé la réduction collective des prix de l'ensemble de l'industrie nationale des grands modèles. Bien que le prix d'appel par million de jetons de la version V4 n'ait pas beaucoup baissé par rapport à ses pairs nationaux, il est toujours compétitif. Le grand boucher des prix des modèles est de retour !""La puissance de calcul de Huawei sera ajoutée par lots au cours du second semestre et le prix Pro sera considérablement réduit."
Il convient de noter qu'au bas des informations sur le prix de l'API publiées par DeepSeek-v4, le responsable a spécifiquement noté : « Limité par la puissance de calcul haut de gamme, le débit actuel du service Pro est très limité, et il devrait monter de 950 super-nœuds au cours du second semestre. Après le lancement en masse, le prix de Pro sera considérablement réduit. "

Cela signifie que les modèles de la série v4 publiés cette fois ont été adaptés pour le super nœud Ascend 950 de Huawei. Tant que l'Ascend 950 sera lancé, la majorité des utilisateurs pourront utiliser DeepSeek-v4 sur la base d'une puissance de calcul nationale comparable à celle des meilleurs modèles internationaux à source fermée.
Dans le document technique open source officiel, DeepSeek l'a également mentionné, affirmant que la v4 a été implémentée sur le GPU NVIDIA et HUAWEI Ascend. Le schéma EP (parallélisme expert) à granularité fine a été vérifié sur la plate-forme NPU. Par rapport à la puissante base de référence sans fusion, il peut obtenir un effet d'accélération de 1,50 à 1,73 fois sur les tâches de raisonnement général, et peut atteindre un effet d'accélération de 1,96 fois dans des scénarios sensibles aux délais (tels que la déduction RL et les services proxy à grande vitesse).

Après la sortie de la V4, Huawei Ascend a également annoncé que « toute la gamme de produits super-nœuds prend en charge les modèles de la série DeepSeek V4 ». Il est rapporté qu'Ascend 950 réduit la surcharge de calcul de l'attention et d'accès à la mémoire en intégrant la technologie parallèle du noyau et multi-flux, améliorant considérablement les performances d'inférence et combinant plusieurs algorithmes de quantification pour obtenir un déploiement d'inférence de modèle DeepSeek V4 à haut débit et à faible latence.
Plus tôt ce mois-ci, le fondateur de NVIDIA, Huang Jensen, acceptait Dwarkesh. Dans une interview exclusive, Patel a déclaré : « Si DeepSeek est d'abord publié sur la plate-forme Huawei, ce sera désastreux pour notre pays (les États-Unis). » Selon Huang Renxun, bien que DeepSeek soit un modèle open source et puisse également être utilisé sur les produits NVIDIA, si DeepSeek est spécifiquement optimisé pour la puissance de calcul de Huawei, NVIDIA sera désavantagé en raison de limitations telles que les restrictions sur l'achat de puissance de calcul haut de gamme.
Il semble maintenant que, bien que DeepSeek ait également vérifié la solution EP pour la puissance de calcul de Nvidia, ce qui inquiétait Huang Renxun est toujours arrivé. Aux yeux des initiés de l'industrie, « le V4 est un produit forcé par la puissance de calcul. Au cours de l'année prochaine, les grands modèles nationaux mûriront progressivement lorsqu'ils fonctionneront sur des cartes nationales ».
Les capacités multimodales ne sont pas encore apparues.
Malheureusement, bien que DeepSeek V4 ait été publié, cette version est toujours un modèle de texte pur sans de nombreuses capacités multimodales telles que les images de Vincent et les vidéos de Vincent. Cela permet également aux utilisateurs ordinaires d'expérimenter et d'évaluer rapidement un modèle, ce qui ajoute beaucoup de difficulté.

Après tout, à mesure que les capacités des grands modèles de langage continuent de s'améliorer et que le taux d'hallucinations diminue progressivement, il est difficile pour les questions et réponses de connaissances conventionnelles et uniques de refléter objectivement les capacités globales d'un modèle. Pour la plupart des utilisateurs, s’ils souhaitent expérimenter intuitivement les capacités du modèle V4, ils doivent le télécharger et l’utiliser personnellement pendant un certain temps.
Parallèlement à la sortie de la série de modèles V4, DeepSeek a également récemment révélé son intention de lever 50 milliards de yuans. Des personnes proches de DeepSeek ont révélé que la valorisation du préfinancement de DeepSeek s'élève à 300 milliards de yuans, soit environ 44 milliards de dollars. Actuellement, Tencent Holdings et Alibaba Group négocient pour investir dans DeepSeek. Cependant, DeepSeek n'a pas répondu directement aux demandes des médias concernant des questions liées au financement.
Peut-être que, pour le fondateur de DeepSeek, Liang Wenfeng, c'est une sage décision d'utiliser la sortie de la V4 pour lever des financements en temps opportun afin de renforcer sa force alors que la croissance de « l'intelligence » des grands modèles mondiaux ralentit, que la concurrence pour les talents de l'industrie s'intensifie et que les tendances multimodales et agentiques de l'industrie sont de plus en plus mises en avant.