GPT-5.6 est là, mais... de quel modèle s'agit-il ? Cette fois, OpenAI n'a pas utilisé les noms familiers de Pro, Mini et Instant dans le passé. Au lieu de cela, il a proposé trois noms à la fois :GPT-5.6 Sol, GPT-5.6 Terre, GPT-5.6 Lune.Sol est le soleil, Terra est la terre et Luna est la lune.
Cela semble sophistiqué, comme un nouvel univers modèle. Mais c'est en fait la superposition de produits que nous connaissons : le modèle phare le plus puissant, un modèle équilibré pour un usage quotidien et un modèle léger, bon marché, rapide et adapté aux appels à grande échelle.
La déclaration officielle d’OpenAI est la suivante :La série GPT-5.6 sera entièrement ouverte dans les semaines à venir, mais est actuellement en avant-première limitée à un petit groupe de « partenaires de confiance » dans le Codex et l'API à la demande du gouvernement américain.
Jetons d'abord un coup d'œil aux renseignements accessibles au public.

La note la plus élevée est au même prix que GPT 5.5
OpenAI a attribué cette fois à GPT-5.6 trois niveaux : Sol, Terra et Luna.
Selon le communiqué officiel, Sol est le modèle phare, Terra est un modèle équilibré pour le travail quotidien et Luna est un modèle rapide, bon marché et léger.
Les modèles à trois niveaux ont été lancés en une seule fois, correspondant essentiellement à la structure à trois niveaux la plus courante dans les produits de grande taille : le modèle le plus puissant est responsable de la limite supérieure des capacités, le modèle intermédiaire est responsable de la plupart des tâches quotidiennes et le modèle léger est responsable de la vitesse, du coût et des appels simultanés élevés.
Le niveau des trois se voit à partir du prix.
Selon le prix de l'API annoncé par OpenAI,GPT-5.6 est facturé pour 1 million de jetons : Sol coûte 5 USD pour l'entrée et 30 USD pour la sortie ; Terra coûte 2,5 dollars américains pour les intrants et 15 dollars américains pour les résultats ; et Luna coûte 1 $ US pour l'entrée et 6 $ US pour la sortie.
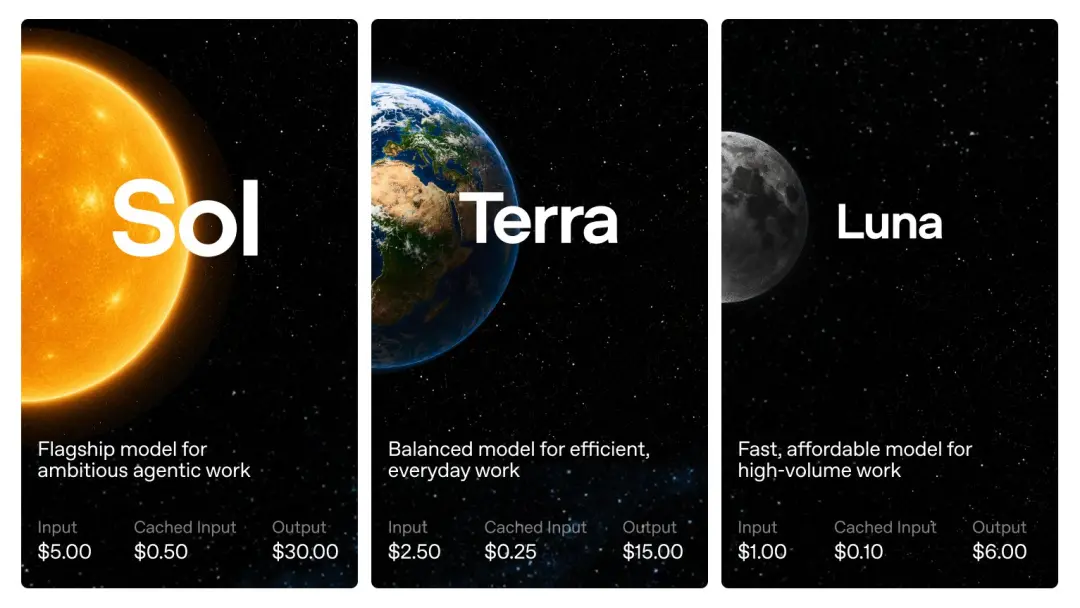
Je pense que vous l'avez peut-être remarqué : bien que le GPT-5.6 Sol soit un modèle phare de nouvelle génération, le prix est aligné sur la version standard du GPT-5.5, et non sur le GPT-5.5 Pro.
Terra est tombé directement à la moitié de GPT-5.5, et Luna n'était qu'à un cinquième de GPT-5.5.
GPT-5.5 Pro reste actuellement le modèle d’OpenAI le plus cher. Le prix est de 30 USD/million de jetons pour l'entrée et de 180 USD/million de jetons pour la sortie. Le prix est 6 fois supérieur à celui de la version standard GPT-5.5 et du GPT-5.6 Sol. Je ne sais pas s’il y aura à l’avenir un autre univers GPT-5.6 qui sera « plus adapté aux tâches professionnelles » (je plaisante).
Sol est le modèle haut de gamme de cette série GPT-5.6, et c'est aussi le modèle qui passe le plus de temps à être présenté dans l'annonce officielle.
OpenAI considère GPT-5.6 Sol comme le modèle le plus puissant actuellement, en se concentrant sur ses capacités en matière de codage, de recherche biologique et de sécurité des réseaux.
Pour faire simple, Sol se positionne comme « le meilleur modèle ». Cela ne correspond pas à des scénarios de chat ordinaires, mais à des tâches plus complexes et plus proches du travail réel.
Par exemple, dans un scénario de code, il peut continuer à avancer autour d'un objectif : d'abord comprendre le problème, puis décomposer les étapes, puis appeler des outils, exécuter des commandes, vérifier les résultats et apporter des corrections si des erreurs surviennent jusqu'à ce que la tâche soit terminée.
Afin d'aider Sol à traiter des tâches plus difficiles, OpenAI a introduit deux nouveaux mécanismes dans GPT-5.6.
Le premier s'appelleeffort de raisonnement maximum, que l'on peut traduire par « force de raisonnement maximale ».
La compréhension populaire signifie que Sol a plus de temps pour réfléchir clairement au problème et prend plus de temps pour mener un raisonnement approfondi. Il convient aux tâches complexes qui ne peuvent être résolues par la première réaction.
Le deuxième s'appellemode ultra,Cela peut être compris comme un « super mode ».
L'objectif de ce modèle est de permettre à plusieurs sous-agents de participer ensemble à des tâches complexes. Cela peut être compris comme suit : dans le passé, un assistant IA travaillait seul, mais désormais un « gestionnaire IA » conduit plusieurs assistants à traiter les problèmes séparément, accélérant ainsi l'avancement des travaux complexes.
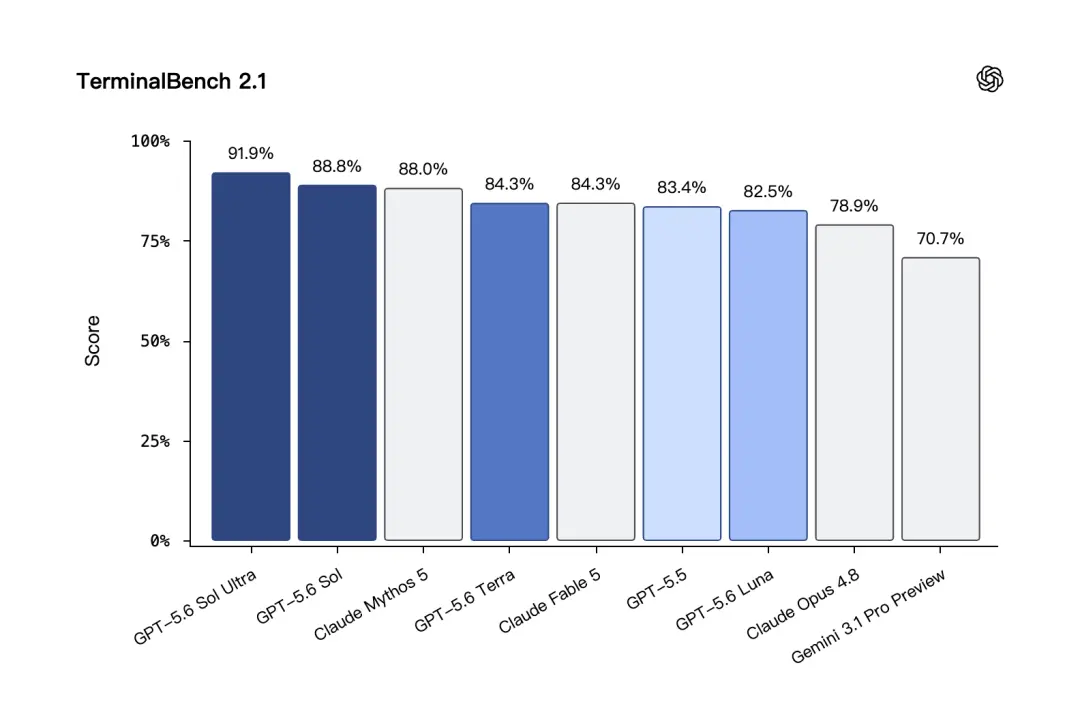
Terminal-Bench 2.1 est un test plus proche du processus de développement réel. Il teste si le modèle peut résoudre le problème étape par étape dans l'environnement de ligne de commande. GPT-5.6 Sol a obtenu un score élevé de 88,8 % dans ce test, et le score était encore plus élevé en mode Ultra.
OpenAI a spécifiquement mentionné que lorsque le modèle sera plus largement ouvert, un ensemble plus complet de résultats d'évaluation sera annoncé.
Terra est le milieu de gamme.
L’introduction d’OpenAI à Terra n’est pas si longue, mais son positionnement est clair : c’est un modèle équilibré pour le travail quotidien.
C’est-à-dire qu’il ne vise pas nécessairement le plus fort, mais qu’il établit un équilibre entre effet, rapidité et coût. Les responsables ont souligné que les capacités de Terra sont proches de GPT-5.5, mais que le prix est la moitié du prix.
Selon la vision d'OpenAI, Terra est probablement le plus couramment utilisé de la série GPT-5.6. Les tâches de bureau ordinaires ne nécessitent souvent pas les capacités les plus élevées comme Sol, mais elles doivent être stables, bon marché et faciles à utiliser.
Dans le test Terminal-Bench 2.1,GPT-5.6 Terra a obtenu 84,3 %, ce qui équivaut à Claude Fable 5.
Luna est la tranche la moins chère.
Le positionnement de Luna par OpenAI est également très simple : rapide, bon marché et adapté aux tâches à grande échelle, à haute fréquence et sensibles aux coûts.
Par exemple, la synthèse par lots, la classification de textes, l'extraction d'informations, les questions et réponses simples, etc. Ces tâches en elles-mêmes ne sont pas nécessairement complexes, mais le volume d'appels peut être très important. Le rôle de Luna est d'exécuter ces tâches légères à moindre coût.
Parmi ces trois modèles, Sol est responsable des capacités les plus élevées, Terra est responsable du travail quotidien et Luna est responsable de la rapidité et du coût. Cela semble sophistiqué, mais OpenAI ne fait que reconditionner les couches déjà matures de la grande industrie du modélisme.
Mais je pense que le nom n’a pas d’importance, tant qu’il est bon marché et facile à utiliser.

Rapport qualité/prix
Rien qu'en regardant l'annonce officielle, les benchmarks publiés par GPT-5.6 Sol cette fois ne sont pas nombreux. OpenAI lui-même a déclaré qu'il s'agissait désormais simplement d'informer le monde extérieur à l'avance des performances du modèle, il partagerait donc d'abord un ensemble de résultats d'évaluation.
Mais l’ensemble de références publié a une direction claire, se concentrant sur trois domaines : le code, la biologie et la sécurité des réseaux.
Le Terminal-Bench 2.1 susmentionné appartient à la direction du code. Il teste si le modèle peut compléter le processus de développement réel dans l'environnement de ligne de commande, y compris la planification, les modifications répétées, l'appel d'outils et la vérification des résultats.
En plus du code, OpenAI a également mis en avant un benchmark biologique : GeneBench v1.
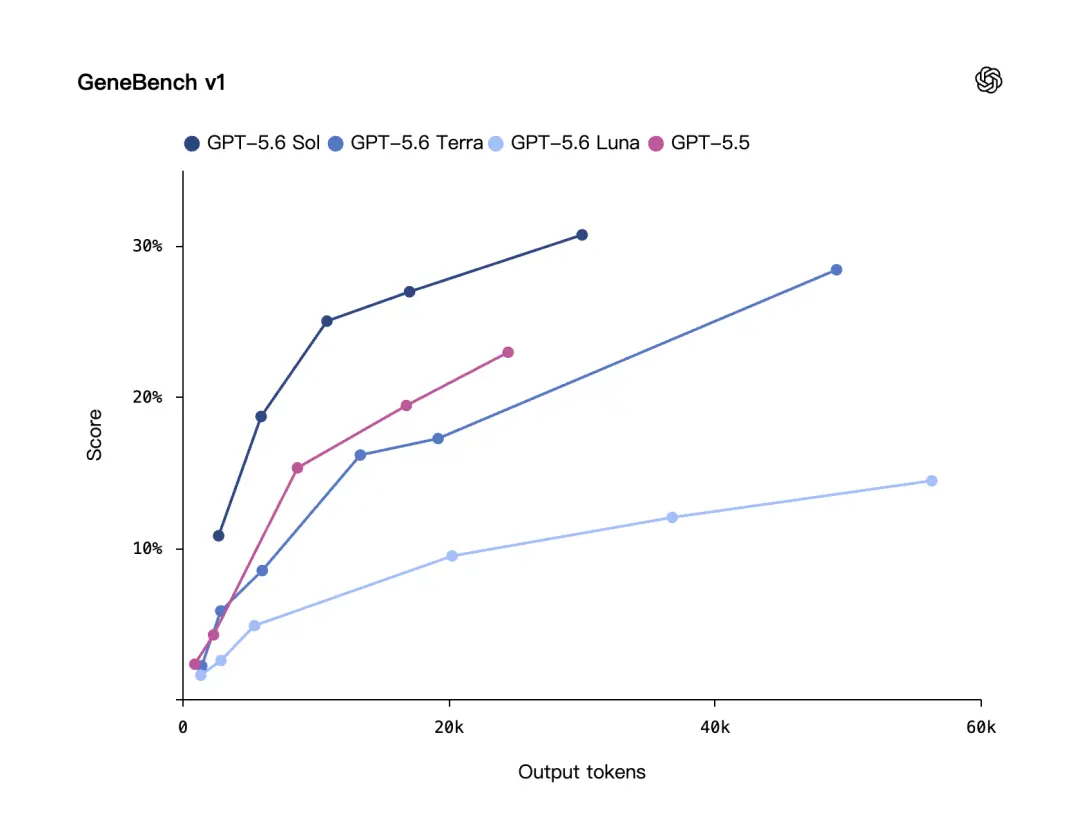
GeneBench v1 évalue les tâches d'analyse génomique et biologique quantitative à long terme, en se concentrant sur la capacité du modèle à résoudre des problèmes d'analyse plus proches du véritable processus de recherche scientifique.
Selon OpenAI, GPT-5.6 Sol fonctionne mieux que GPT-5.5 sur GeneBench v1, etUtilisez moins de jetons.
La troisième direction clé est la sécurité des réseaux. OpenAI affirme que GPT-5.6 Sol est actuellement son modèle de sécurité réseau le plus solide, en particulier pour les tâches de sécurité à long terme (y compris les tâches liées à la recherche et à l'exploitation des vulnérabilités).
Il existe ici un benchmark appelé ExploitBench - il ne s'agit pas d'une question et d'une réponse de sécurité générale, mais d'une évaluation plus proche des scénarios d'exploitation des vulnérabilités.
OpenAI a déclaré que sur ExploitBench,Les performances de GPT-5.6 Sol sont comparables à celles de Mythos Preview, mais n'utilisent qu'environ un tiers des jetons de sortie.
Cependant, il existe encore une certaine lacune dans la situation officielle.
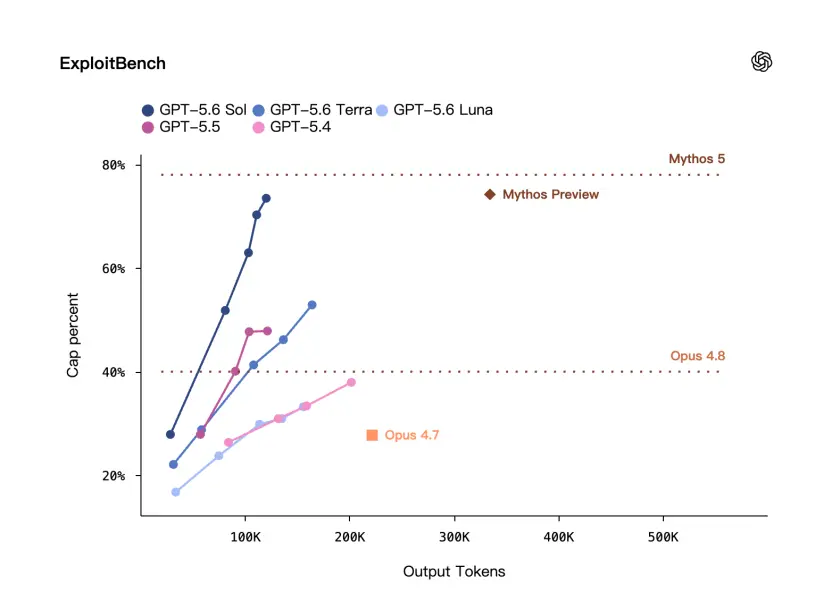
On peut voir qu'OpenAI a souligné à plusieurs reprises cette fois :Bien qu’ils soient très compétents, ils sont également extrêmement efficaces.
Moins de jetons de sortie signifient que le modèle peut être plus concis et comporter moins de détours lors de l'exécution de tâches similaires, et cela peut également signifier que le coût réel des appels est plus contrôlable.
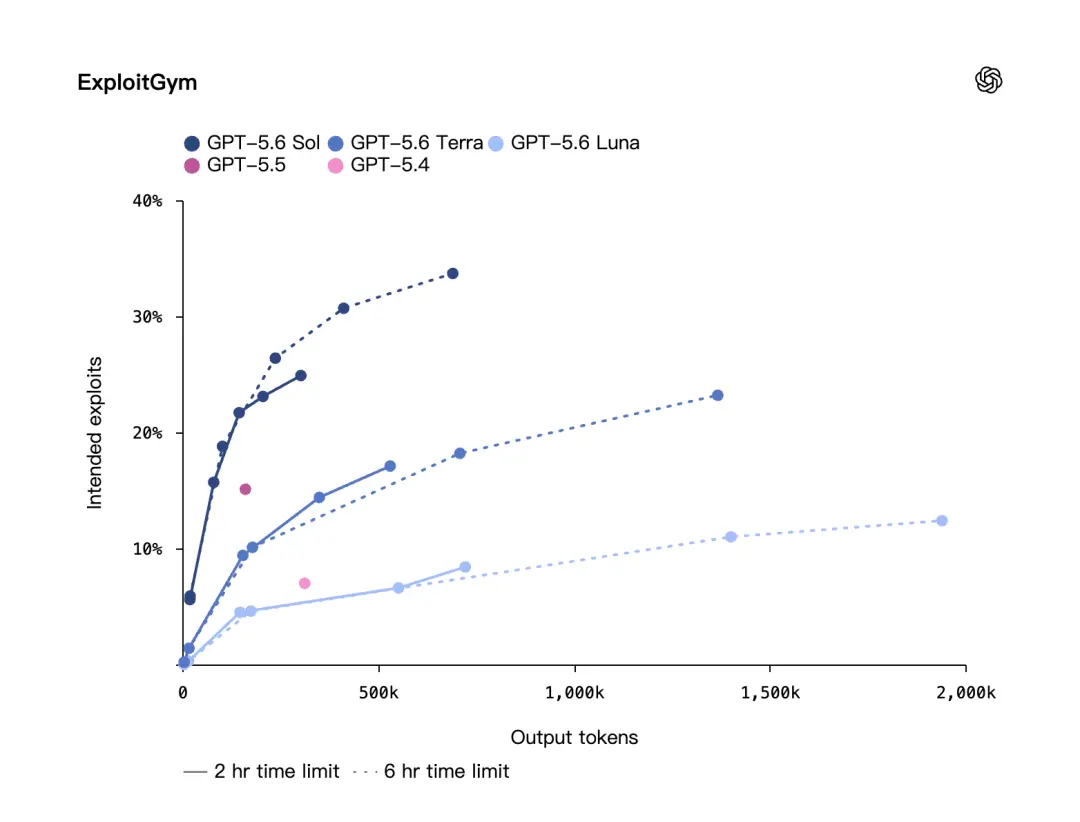
OpenAI a également mentionné une autre référence en matière de cybersécurité : ExploitGym.
Cette référence a été créée par des chercheurs de l'UC Berkeley en collaboration avec OpenAI et d'autres laboratoires de pointe. OpenAI a déclaré que sur ExploitGym, les modèles GPT-5.6 Sol, Terra et Luna montrent tous une amélioration significative des capacités de sécurité du réseau et qu'à mesure que l'intensité de l'inférence augmente, les performances deviendront plus fortes.
Cela signifie que l'amélioration de GPT-5.6 ne concerne pas seulement le corps du modèle plus solide, mais également la méthode de raisonnement. Donnez au modèle plus de temps pour réfléchir et laissez-le effectuer une chaîne de raisonnement plus longue, et les résultats seront meilleurs.

À propos de l'aperçu limité
Si Sol, Terra et Luna sont des changements superficiels de GPT-5.6, alors ce qui mérite plus d'attention est qu'OpenAI n'a pas été complètement ouvert cette fois.
Selon l'annonce officielle, GPT-5.6 ne sera actuellement disponible qu'en aperçu limité dans le Codex et l'API pour un petit groupe de « partenaires dignes de confiance ».
De plus, cette avant-première limitée a été réalisée « à la demande du gouvernement américain » et la liste des partenaires participant à l’avant-première a été partagée avec le gouvernement américain.
Ces derniers temps, le gouvernement américain a considérablement accru son implication dans les modèles d’IA de pointe, en particulier ceux dotés d’un code, d’une sécurité réseau et de capacités d’agent plus solides.
En juin de cette année, le gouvernement américain a publié un nouveau décret relatif à la cybersécurité de l'IA, proposant d'établir un cadre volontaire pour permettre aux développeurs de modèles de pointe de contacter et d'évaluer le modèle avant sa diffusion plus large.
L'interprétation de cet ordre administratif par la communauté juridique est qu'il ne s'agit pas d'une licence obligatoire en soi, ni d'un système d'approbation formel, mais qu'il a établi un cadre institutionnel pour la participation du gouvernement à l'évaluation préalable du modèle.
Le modèle de publication de GPT-5.6 Sol consistant à « prendre un aperçu à petite échelle et partager la liste avec le gouvernement » peut être considéré comme la première trace claire de l'intervention du gouvernement dans le processus de publication du modèle de pointe.
OpenAI lui-même a également expliqué dans l'annonce que la raison de cette approche est d'explorer un processus reproductible avec le gouvernement pour soutenir les futures versions de modèles.
La principale raison de l’intervention gouvernementale est la sécurité des réseaux.
Dans l'annonce officielle, la sécurité du réseau occupe beaucoup de place : OpenAI souligne que GPT-5.6 Sol est actuellement son modèle de sécurité réseau le plus solide et peut fournir une aide plus importante dans les tâches à long terme telles que la recherche de vulnérabilités, l'analyse des vulnérabilités et la défense de sécurité ; en revanche, il consacre beaucoup d'espace à expliquer qu'il n'a pas franchi son propre seuil Cyber Critique.
Dans le cadre de préparation d’OpenAI, les capacités à haut risque sont divisées en différents niveaux. Atteindre un niveau élevé signifie que le modèle peut amplifier les risques graves existants ; atteindre le niveau critique signifie que le modèle peut engendrer des risques graves nouveaux et sans précédent.
OpenAI a souligné à plusieurs reprises que GPT-5.6 Sol n'atteint pas Cyber Critical. En fait, il dit au gouvernement, aux clients et au public : ce modèle est très solide, en particulier dans les tâches de sécurité des réseaux, mais il n'est pas assez puissant pour mener à bien de manière indépendante les chaînes d'attaques réseau les plus dangereuses.
Les capacités de sécurité des réseaux sont comme une arme à double tranchant. Plus ils sont forts, plus ils peuvent aider les défenseurs à trouver des vulnérabilités, à rédiger des correctifs et à effectuer des tests de sécurité ; mais précisément parce qu’ils sont si forts, le gouvernement s’inquiétera également de leurs abus.
Bien qu'OpenAI ait admis que cette version nécessite d'explorer le processus avec le gouvernement, il a également clairement indiqué dans l'annonce officielle qu'il ne pensait pas que ce processus d'accès gouvernemental devrait devenir le mécanisme par défaut à long terme.
La justification : si les outils les plus puissants sont retardés, les utilisateurs, les développeurs, les entreprises, les défenseurs des réseaux et les partenaires du monde entier tarderont à obtenir les meilleurs outils.
En un sens, les modèles de pointe entrent dans une nouvelle phase de sortie.
Lorsque les capacités des grands modèles seront concentrées dans des domaines tels que le code, la biologie, la sécurité des réseaux et l’exécution des agents, ils commenceront à être considérés comme une technologie susceptible d’avoir un impact sur la sécurité du monde réel.
Une fois la technologie considérée de cette manière, il est difficile que les droits d’édition restent entièrement entre les mains de l’entreprise elle-même.