AMD promeut une vision de l'intelligence artificielle qui ne repose pas sur le cloud. Son nouveau framework OpenClaw, associé à deux ensembles de configurations matérielles de référence RyzenClaw et RadeonClaw, est conçu pour permettre aux développeurs et aux premiers utilisateurs d'exécuter de grands modèles de langage et des flux de travail multi-agents sur des PC locaux. Cette décision fait partie du plan plus vaste « Agent Computer » d'AMD, qui estime que l'avenir de l'IA ne devrait pas se limiter aux centres de données distants, mais devrait donner aux utilisateurs le contrôle de leurs propres données et de leur environnement informatique, faire fonctionner les assistants d'IA locaux pendant une longue période, réduire les dépendances au réseau et les charges d'abonnement, et atténuer les problèmes de confidentialité.

D'un point de vue technique, OpenClaw fonctionne actuellement sur la plate-forme Windows via WSL2 (sous-système Windows pour Linux 2), et LM Studio est utilisé avec le backend llama.cpp pour entreprendre des tâches d'inférence locales. Dans cet environnement, les utilisateurs peuvent exécuter des modèles dont Qwen 3.5 35B A3B directement sur la machine. Le système prend également en charge un cadre de mémoire intégré appelé Memory.md pour stocker des informations contextuelles localement sans recourir à la synchronisation cloud. AMD positionne le didacticiel officiel comme un chemin de configuration relativement simplifié pour permettre aux développeurs de créer un environnement OpenClaw complet sur Windows et de tester l'architecture de l'agent AI, mais le document ne donne pas de temps de configuration estimé clair.

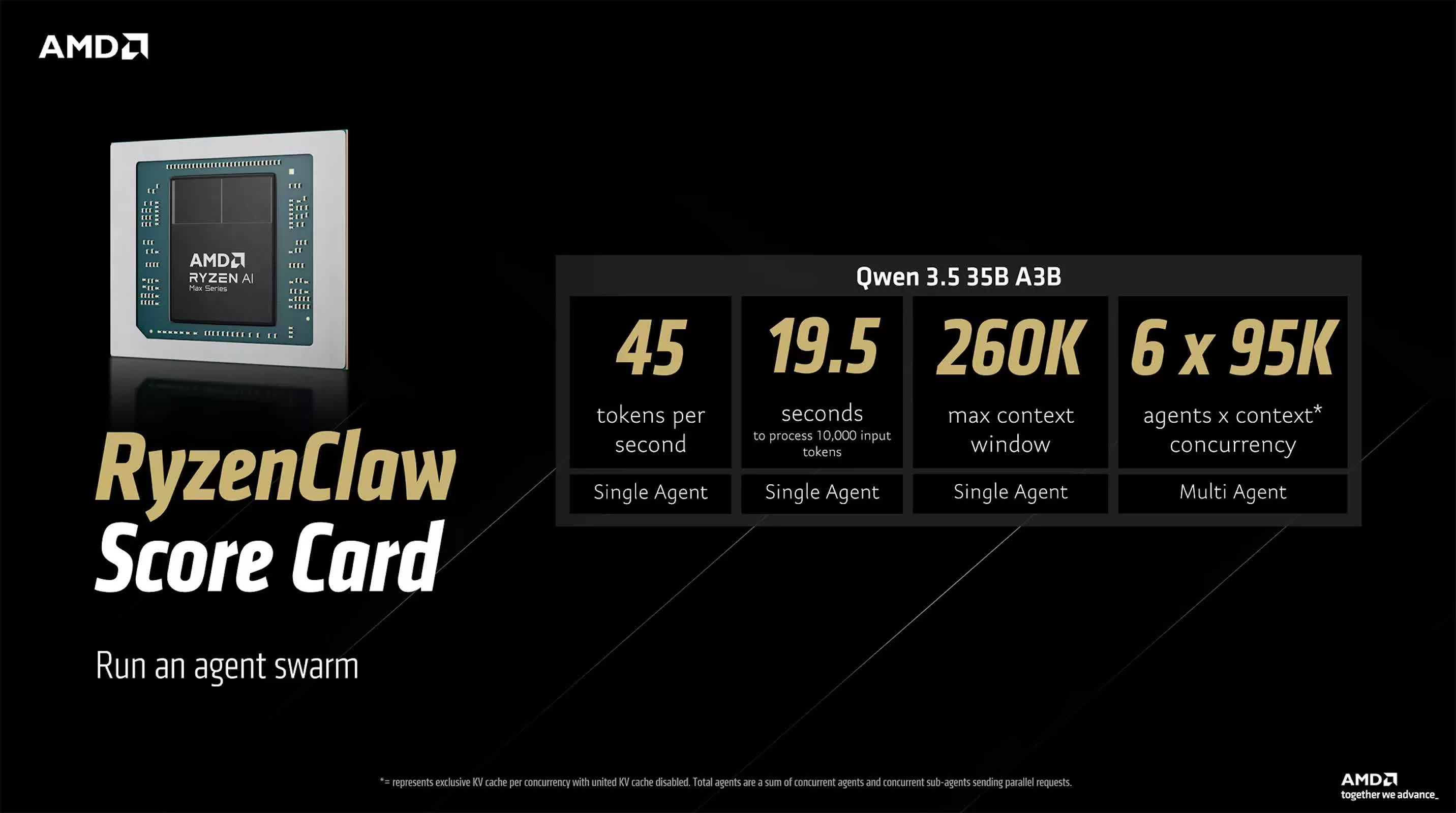
Les deux références OpenClaw proposées par AMD représentent des voies différentes vers une « IA native haute performance ». La solution RyzenClaw est construite autour du processeur Ryzen AI Max+ et est équipée de 128 Go de mémoire unifiée, dont AMD recommande qu'environ 96 Go soient alloués en tant que mémoire vidéo variable pour garantir l'efficacité de l'inférence de grands modèles. Dans cette configuration, Qwen 3.5 35B A3B génère environ 45 jetons par seconde, prend environ 19,5 secondes pour traiter une entrée de 10 000 jetons, prend en charge une fenêtre contextuelle d'environ 260 000 jetons et peut être utilisé dans des flux de travail multi-agents ou des environnements expérimentaux de « cluster d'agents ». AMD affirme que la plate-forme peut exécuter simultanément jusqu'à six agents d'IA locaux, ce qui est typique des systèmes autres que les centres de données.

Une autre configuration RadeonClaw déplace la puissance de calcul vers le GPU indépendant - Radeon AI PRO R9700. Cette carte graphique de classe station de travail offre 32 Go de mémoire graphique dédiée, augmentant considérablement le débit d'inférence. Sous le même modèle, la vitesse de génération peut être augmentée jusqu'à environ 120 jetons par seconde, réduisant ainsi le temps de traitement d'une entrée de 10 000 jetons à environ 4,4 secondes. Cependant, ce gain de performances s'accompagne de certains compromis : la fenêtre de contexte maximale est réduite à environ 190 000 jetons et le nombre d'agents simultanés est réduit à 2. Ces différences mettent en évidence la tentative d'AMD de fournir différentes voies de réglage permettant aux développeurs de trouver un compromis entre une plus grande profondeur de contexte et une inférence plus rapide en fonction de leurs besoins.
En termes de positionnement, ni RyzenClaw ni RadeonClaw ne sont une configuration d'entrée de gamme destinée aux consommateurs ordinaires. En prenant RyzenClaw comme exemple, un ordinateur de bureau basé sur la puce Ryzen AI Max+ 395 et équipé de 128 Go de mémoire (comme le plan Framework Desktop) commence à environ 2 700 $. Si vous optez pour RadeonClaw, vous devrez également acheter la carte graphique Radeon AI PRO R9700, qui à elle seule a un prix de détail suggéré d'environ 1 299 $. AMD admet actuellement que les principaux utilisateurs cibles d'OpenClaw sont les ingénieurs et les premiers utilisateurs qui expérimentent des agents d'IA locaux, plutôt que les utilisateurs de PC traditionnels.

Pourtant, le message d'OpenClaw va au-delà du matériel spécifique lui-même. AMD parie sur une tendance dans laquelle les développeurs privilégieront l'autonomie et la confidentialité plutôt que l'expansion à l'échelle du cloud, dans l'espoir de construire un pont entre l'informatique personnelle et l'IA distribuée via des agents locaux fonctionnant sur des puces grand public. Si cette idée est reconnue par l'écosystème, AMD devrait occuper une position unique dans le paysage de l'IA en évolution rapide, permettant à certains ordinateurs de bureau et postes de travail haut de gamme de disposer progressivement de capacités de traitement de l'IA proches des centres de données, tout en conservant un sentiment de contrôle et de flexibilité du côté de l'utilisateur.