OpenAI a lancé mardi ses deux petits modèles les plus puissants à ce jour, GPT-5.4 mini et GPT-5.4 nano, réduisant considérablement l'écart de performances avec les modèles phares avec une latence et un coût inférieurs.GPT-5.4 mini surpasse la génération précédente GPT-5 mini dans des dimensions essentielles telles que la programmation, le raisonnement, la compréhension multimodale et l'invocation d'outils. La vitesse de fonctionnement est multipliée par plus de 2 et est proche du plus grand GPT-5.4 dans les tests de référence tels que SWE-Bench Pro.
GPT-5.4 nano se positionne comme l'option légère avec le coût le plus bas et la latence la plus courte. Il est uniquement ouvert aux développeurs via l'API et est conçu pour la classification, l'extraction et les sous-tâches de programmation simples.
Le lancement des deux modèles vise à combler le vide dans lequel les grands modèles sont difficiles à mettre en œuvre dans des scénarios d'interaction en temps réel en raison de retards élevés, affectant directement le marché commercial en croissance rapide couvrant les assistants de programmation, les systèmes d'agents d'IA et les applications multimodales.
mini est destiné au consommateur et l'API exclusive de nano
GPT-5.4 mini sera lancé simultanément sur les trois principaux canaux de l'API OpenAI, de la plateforme Codex et de ChatGPT à partir d'aujourd'hui.
Le prix de l'API de GPT-5.4 mini est de 0,75 USD par million de jetons d'entrée et de 4,50 USD par million de jetons de sortie., prend en charge la saisie de texte et d'images, l'appel d'outils, l'appel de fonctions, la recherche sur le Web, la récupération de fichiers, le contrôle informatique et l'expansion des compétences, et la fenêtre contextuelle atteint 400 000 jetons.
Sur la plate-forme Codex, GPT-5.4 mini ne consomme que 30 % du quota GPT-5.4, et le coût pour les développeurs pour gérer des tâches de programmation simples est réduit à environ un tiers de celui du modèle phare.Codex prend également en charge la délégation de charges de travail à des sous-agents exécutés dans GPT-5.4 mini, permettant aux tâches moins gourmandes en inférence de tomber automatiquement dans des modèles moins chers.
Côté ChatGPT, les utilisateurs Free and Go peuvent sélectionner la fonction « Thinking » via le menu « + » pour utiliser GPT-5.4 mini ; pour les autres utilisateurs payants, une fois que GPT-5.4 Thinking aura atteint la limite de débit, ce modèle sera activé en tant qu'option de rétrogradation automatique.
GPT-5.4 nano n'est actuellement disponible que pour les développeurs via l'API et son prix est de 0,20 USD par million de jetons d'entrée et de 1,25 USD par million de jetons de sortie, ce qui en fait le prix le plus bas des deux nouveaux modèles. OpenAI a déclaré que nano convient aux scénarios de sous-agents coordonnés et planifiés par des modèles d'ordre élevé et responsables du traitement des tâches de support secondaires.
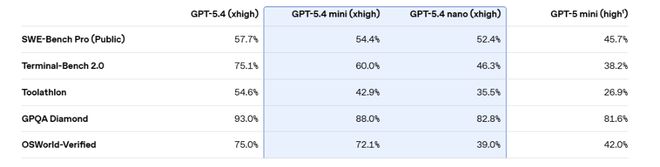
mini se rapproche du produit phare, nano surpasse la génération précédente
À en juger par les données d'évaluation publiées par OpenAI, GPT-5.4 mini fonctionne particulièrement bien dans la programmation et les tâches multimodales.
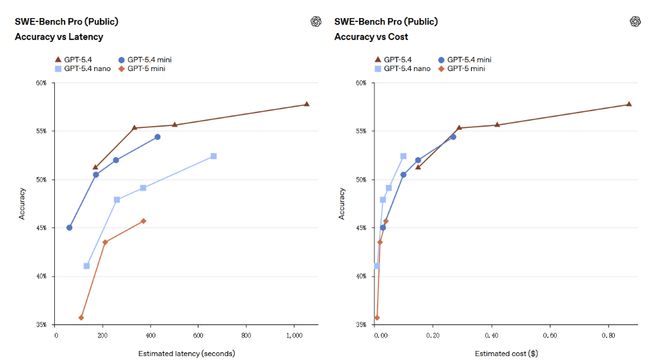
Sur le benchmark de programmation SWE-bench Pro, mini a obtenu un score de 54,4 % et l'écart avec les 57,7 % de GPT-5.4 s'est réduit à 3,3 points de pourcentage, bien supérieur aux 45,7 % de GPT-5 mini.

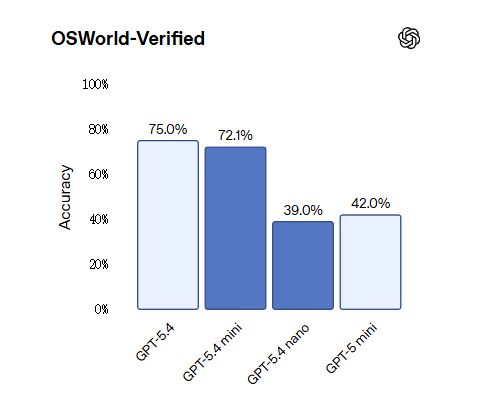
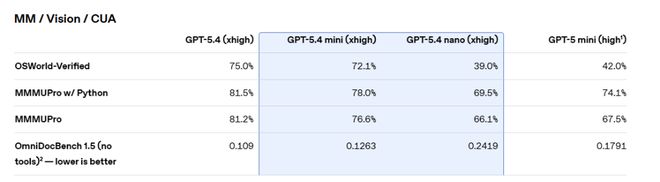
repères contrôlés par ordinateurSur OSWorld-Verified, mini se rapproche des 75,0 % de GPT-5.4 avec 72,1 %, et est nettement en avance sur les 42,0 % de GPT-5 mini.
Capacité d'appel d'outil, GPT-5.4 mini a obtenu un score de 93,4 % au test de télécommunications sur banc τ2, une amélioration significative par rapport aux 74,1 % du GPT-5 mini. Dans le test d'intelligence générale GPQA Diamond, mini a obtenu un score de 88,0 % et nano a également atteint 82,8 %, tous deux dépassant les 81,6 % du GPT-5 mini.

Il convient de noter que GPT-5.4 nano est en retard sur GPT-5 mini dans certaines tâches visuelles, avec un score OSWorld-Verified de 39,0 % inférieur aux 42,0 % de ce dernier. Cependant, en termes de tâches de programmation et d’appel d’outils, nano est encore considérablement amélioré par rapport à la génération précédente.
OpenAI a déclaré que la priorité de conception de nano est une faible latence et un faible coût, plutôt que des performances complètes. Les développeurs doivent faire des compromis en fonction de tâches spécifiques lors de la sélection.
Architecture de sous-agents et collaboration multi-modèles deviennent un nouveau paradigme de conception de produits
Dans ses documents de publication, OpenAI a souligné la position des deux nouveaux modèles dans le système hiérarchique multimodèle.
En prenant comme exemple son assistant de programmation auto-développé Codex, GPT-5.4 est responsable de la planification, de la coordination et du jugement final, tandis que le mini sous-agent GPT-5.4 gère en parallèle des sous-tâches plus fines telles que la récupération de la base de code, l'examen de fichiers volumineux et le traitement de documents auxiliaires.
OpenAI a déclaré qu'à mesure que les petits modèles deviennent plus rapides et plus puissants, les développeurs n'ont plus besoin d'utiliser un seul modèle pour gérer toutes les tâches, mais peuvent créer des systèmes dans lesquels les grands modèles sont responsables de la prise de décision et les petits modèles exécutent les tâches rapidement et à grande échelle.OpenAI a dit :
Le GPT-5.4 mini est notre petit modèle le plus puissant à ce jour pour ce flux de travail.
Cette architecture est particulièrement critique pour les travaux à haute concurrence. Dans des scénarios tels que les assistants de programmation, l'analyse de captures d'écran et la compréhension d'images en temps réel, les délais de réponse affectent directement la sensation du produit. Le choix optimal n’est souvent pas le modèle doté des capacités les plus puissantes, mais celui qui permet d’atteindre le meilleur équilibre entre vitesse, fiabilité de l’outil et performance des tâches.
Pour les développeurs, la sortie de GPT-5.4 mini et nano signifie que la voie à suivre pour réduire considérablement les coûts d'inférence sans sacrifier l'intelligence globale du système est encore plus claire.