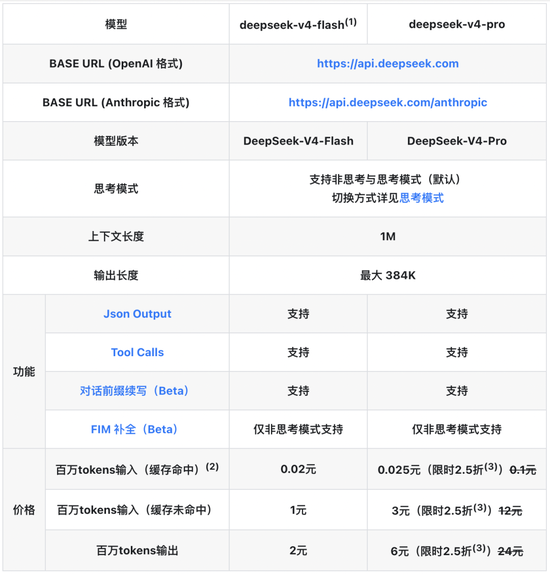
DeepSeek redéfinit les limites de l'inclusion de grands modèles. Le 26 avril, DeepSeek a officiellement publié une annonce d'ajustement des prix de l'API. Le prix de tous les accès au cache d'entrée de l'API a été réduit à un dixième du prix initial. La mise à niveau V4‑Pro bénéficie d'une réduction de 25 % pour une durée limitée, et les accès au cache d'entrée d'un million de jetons sont aussi bas que 0,025 yuan, établissant un nouveau plus bas dans le prix des grands modèles dans le monde.

Selon l'annonce sur la page officielle de tarification de l'API de DeepSeek, cette réduction de prix couvre tous les modèles de la série V4, et les ajustements de base se concentrent sur les scénarios d'atteinte du cache d'entrée. Parmi eux, le prix du cache d'entrée DeepSeek-V4-Flash est passé de 0,2 yuan/million de jetons à 0,02 yuan/million de jetons.
DeepSeek-V4-Pro pour les utilisateurs de niveau entreprise propose des réductions encore plus importantes. Le prix initial de 1 yuan/million de jetons est réduit à 0,1 yuan pour l'entrée du cache. Une offre spéciale de 25 % de réduction à durée limitée est ajoutée avant le 5 mai 2026, ce qui ne représente en réalité que 0,025 yuan/million de jetons. L'entrée manquante dans le cache est réduite de 12 yuans à 3 yuans, et la sortie est réduite de 24 yuans à 6 yuans.
Source de l'image : site officiel de DeepSeek
DeepSeek a mentionné que les deux noms de modèles DeepSeek-Chat et DeepSeek-Reasoner seront obsolètes à l'avenir. Pour des raisons de compatibilité, les deux correspondent respectivement aux modes de non-réflexion et de réflexion de DeepSeek-V4-Flash.
En comparant les prix avant et après l'ajustement des prix, il est facile de constater que le coût des appels à haute fréquence et des scénarios de traitement de textes longs a diminué de plus de 90 %. Les applications avec des taux de réussite élevés dans le cache, telles que la base de connaissances RAG, le service client intelligent et l'analyse de documents, peuvent directement entraîner une chute vertigineuse des coûts commerciaux, contribuant ainsi à briser les chaînes financières de la mise en œuvre à grande échelle de l'IA.
La réduction significative du prix de DeepSeek est liée à la mise à niveau technologique de DeepSeek‑V4 et à la collaboration approfondie avec l'écosystème Shengteng.
Le 24 avril, la version préliminaire de DeepSeek‑V4 a été officiellement publiée. Les modèles open source Pro et Flash prennent en charge 1 million de contextes ultra-longs de jetons. L'architecture d'attention clairsemée auto-développée réduit considérablement la consommation de puissance de calcul d'inférence. La puissance de calcul à jeton unique de la version Pro ne représente que 27 % de celle de la V3.2 et le cache KV est réduit à 10 %, permettant ainsi une optimisation des coûts de bas en haut.
Les paramètres annoncés par DeepSeek montrent que DeepSeek‑V4‑Pro dispose de 49 B de paramètres d'activation et de 33 T de données de pré-entraînement, le positionnant comme un produit phare hautes performances ; DeepSeek‑V4‑Flash dispose de 13 B de paramètres d'activation et de 32 T de données de pré-entraînement, se concentrant sur la vitesse élevée et le faible coût.
Par rapport au modèle de génération précédente, les capacités d'agent de DeepSeek-V4-Pro sont considérablement améliorées. Dans l'évaluation Agentic Coding, V4-Pro a atteint le meilleur niveau des modèles open source actuels et a également obtenu de bons résultats dans d'autres évaluations liées aux agents. Il est rapporté que DeepSeek-V4 est devenu le modèle de codage agent utilisé par les employés internes de DeepSeek. Selon les retours d'évaluation, l'expérience d'utilisation est meilleure que celle de Sonnet 4.5, et la qualité de livraison est proche du mode sans réflexion de Claude Opus 4.6, mais il existe encore un certain écart avec le mode de réflexion Opus 4.6.
Dans l'évaluation des connaissances mondiales, DeepSeek-V4-Pro est nettement en avance sur les autres modèles open source et légèrement inférieur au meilleur modèle fermé Gemini-Pro-3.1. Dans l'évaluation des codes mathématiques, STEM et compétitifs, DeepSeek-V4-Pro a surpassé tous les modèles open source actuellement évalués publiquement et était comparable aux meilleurs modèles open source au monde.
Comparé à DeepSeek-V4-Pro, DeepSeek-V4-Flash est légèrement inférieur en termes de réserve mondiale de connaissances, mais il montre des capacités de raisonnement proches. Étant donné que les paramètres et les activations du modèle sont plus petits, V4-Flash peut fournir des services API plus rapides et plus économiques.
DeepSeek-V4 a également été le pionnier d'un nouveau mécanisme d'attention qui se compresse dans la dimension du jeton et le combine avec l'attention sparse DSA (DeepSeek Sparse Attention) pour obtenir des capacités de contexte long de pointe et réduire considérablement les besoins en mémoire informatique et graphique par rapport aux méthodes traditionnelles.
Ce qui est encore plus remarquable, c'est que toute la gamme de produits Ascend super node prend en charge les modèles de la série DeepSeek V4. Cela signifie également que DeepSeek émet davantage de signaux de localisation.
DeepSeek-V4 a mentionné dans un rapport technique : « Le schéma EP (Expert Parallel) à granularité fine a été vérifié sur deux plates-formes, NVIDIA GPU et Huawei Ascend NPU. Par rapport à la puissante ligne de base non fusionnée, le schéma a atteint une accélération de 1,50 à 1,73 fois dans les tâches de raisonnement général ;
DeepSeek a souligné qu'à mesure que la gamme complète de produits Ascend super node sera lancée par lots au cours du second semestre, le prix de la version Pro devrait être considérablement réduit.
Après la sortie de DeepSeek-V4, Goldman Sachs a publié un rapport d'analyse soulignant que l'importance fondamentale de DeepSeek V4 est de prendre en charge la mise en œuvre d'applications d'agents plus complexes à moindre coût, ouvrant ainsi un nouvel espace pour l'échelle des applications d'IA. Concernant l’inclusion des super-nœuds Ascend, Goldman Sachs estime que la compétitivité des coûts de DeepSeek sera encore renforcée, créant ainsi les conditions d’un plus large éventail d’applications. En outre, dans un contexte de resserrement continu des puces, la tendance à migrer les meilleurs modèles d'IA chinois vers la puissance de calcul nationale a été clairement approuvée par les principaux acteurs.
Le rapport de Goldman Sachs cite également des informations selon lesquelles Tencent et Alibaba négocient un investissement dans DeepSeek pour une valorisation de plus de 20 milliards de dollars. Les dernières valeurs marchandes de Zhipu et MiniMax sont respectivement d'environ 53 milliards de dollars et 31 milliards de dollars. Cette transaction potentielle reflète la logique de la concurrence entre les géants pour les rares capacités d'IA de haut niveau.
Huatai Securities estime que le marché interprète facilement la V4 comme « une réduction des coûts et une réduction de la puissance de calcul et des besoins de stockage », mais le changement marginal le plus important est qu'après la diminution du coût du contexte long, la disponibilité d'agents complexes, l'analyse multidocuments, les tâches à long terme, l'apprentissage en ligne et d'autres scénarios augmenteront, et le nombre d'appels d'inférence et la fréquence d'accès au stockage devraient augmenter.