La mauvaise nouvelle est que l’écart entre les modèles open source et fermé se creuse de plus en plus. Bonne nouvelle, DeepSeek est de retour. Le 1er décembre, DeepSeek a publié deux nouveaux modèles : DeepSeek V3.2 et DeepSeek-V3.2-Speciale.
Le premier peut rivaliser avec GPT-5 dans les deux sens, et la dernière version haute performance a directement fait exploser GPT et a commencé à avoir un écart de 50-50 avec le modèle à source fermée plafond-Gemini.
Il a également remporté des médailles d'or dans une série de compétitions telles que l'OMI 2025 (Olympiade mathématique internationale) et la CMO 2025 (Olympiade mathématique de Chine).
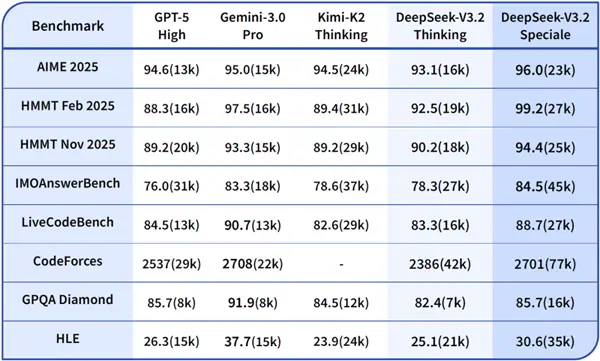
Il s'agit du neuvième modèle lancé par la société cette année, même si le très attendu R2 n'est pas encore là.
Alors, comment DeepSeek utilise-t-il des données plus petites et moins de cartes graphiques pour créer un modèle capable de rivaliser avec les géants internationaux ?
Nous avons ouvert leur journal et avons voulu expliquer clairement cette question à tout le monde.
Afin d’atteindre cet objectif, DeepSeek a mis en place de nombreuses nouvelles astuces :
Tout d'abord, notre vieil ami DSA - Dirty Attention est devenu un habitué.
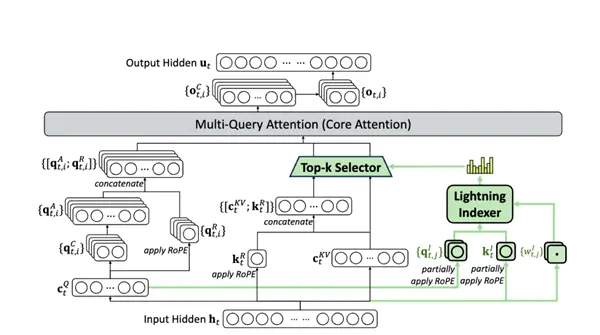
Cette chose est apparue dans la version précédente V3.2-EXP. À cette époque, nous venions de tester si DSA affecterait les performances du modèle. Maintenant, nous avons vraiment mis cette chose sur le modèle principal.

Lorsque vous discutez habituellement avec de grands modèles, vous constaterez que plus vous discutez dans une boîte de dialogue, plus il est facile pour le modèle de dire des bêtises.
Même s’ils parlent trop, ils vous empêcheront de discuter directement.

Il s’agit d’un problème causé par le mécanisme d’attention natif des grands modèles. Sous l'influence de cette ancienne logique, chaque jeton doit être calculé avec chaque jeton précédent.

Cela entraîne le doublement de la peine et le montant du calcul du modèle devant être multiplié par quatre. Si la longueur du côté triple, le montant du calcul devient neuf fois, ce qui est très gênant.
DeepSeek pensait que cela ne fonctionnerait pas, il a donc ajouté un nombre fixe de pages de répertoires (peu d'attention) au grand modèle, ce qui équivaut à aider le modèle à se concentrer.
Une fois que vous avez la table des matières, il vous suffit de calculer la relation entre ce jeton et ces répertoires à chaque fois dans le futur. Cela équivaut à lire d’abord la table des matières lors de la lecture d’un livre. Après avoir lu la table des matières, vous pouvez déterminer quel chapitre vous intéresse, puis lire attentivement le contenu de ce chapitre.
De cette façon, la capacité des grands modèles à lire des textes longs deviendra renforcée.
Comme vous pouvez le voir dans l'image ci-dessous, à mesure que les phrases deviennent de plus en plus longues, le coût de raisonnement de la V3.1 traditionnelle devient de plus en plus élevé.
Mais en utilisant la version 3.2 avec peu d'attention, il n'y a aucun changement...

Je suis un super champion de l'économie d'argent.
D'un autre côté, DeepSeek a commencé à s'intéresser au travail post-formation des modèles open source.
Le processus allant de la pré-formation à la notation des tests pour le grand modèle est en fait un peu comme le processus que nous, les humains, depuis l'école primaire jusqu'à l'examen d'entrée à l'université.
La précédente pré-formation à grande échelle équivaut à parcourir tous les manuels, cahiers d'exercices et devoirs de l'école primaire à la deuxième année du lycée. Cette étape est la même pour tout le monde. Qu'il s'agisse d'un modèle fermé ou d'un modèle open source, ils étudient tous honnêtement.
Mais il en va différemment lorsqu’il s’agit de l’étape sprint de l’examen d’entrée à l’université. Dans la phase post-formation du modèle, les modèles à source fermée embauchent généralement des enseignants célèbres pour rafraîchir les questions, démarrer divers apprentissages par renforcement et enfin laisser le modèle obtenir de bons résultats au test.
Cependant, les modèles open source y consacrent moins de temps. Selon DeepSeek, l’investissement informatique des anciens modèles open source au cours de la phase post-formation était généralement faible.
Cela conduit au fait que ces modèles peuvent avoir des capacités de base en place, mais qu'il y a trop peu de problèmes difficiles à résoudre, ce qui entraîne de mauvais résultats aux tests.
Par conséquent, DeepSeek a décidé cette fois de suivre un cours de tutorat avec des professeurs célèbres et a conçu un nouveau protocole d’apprentissage par renforcement. Après la pré-formation, il a dépensé plus de 10 % de la puissance de calcul totale de la formation pour apporter de petites améliorations au modèle afin de compenser la pièce manquante.
Dans le même temps, une version spéciale capable de réfléchir longtemps - DeepSeek V3.2 Speciale a également été lancée.
L'idée derrière cette chose est la suivante :
Dans le passé, les grands modèles avaient des limites en termes de longueur de contexte, ils effectuaient donc un travail d'étiquetage et de pénalité pendant la formation. Si le contenu de la réflexion approfondie du modèle était trop long, des points seraient déduits.
Quant à DeepSeek V3.2 Speciale, DeepSeek a simplement annulé cet élément de déduction.Au lieu de cela, le modèle est encouragé à réfléchir aussi longtemps et comme il le souhaite.
Au final, ce nouveau DeepSeek V3.2 Speciale a rivalisé avec succès avec le populaire Gemini 3 il y a quelques jours.
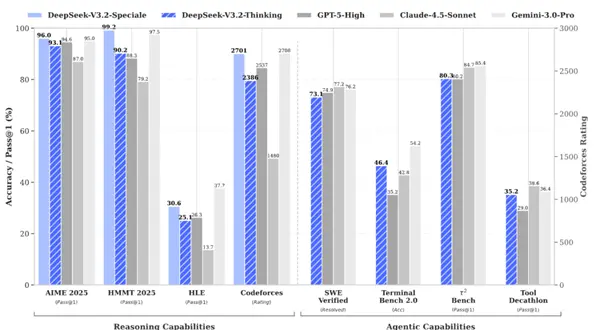
De plus, DeepSeek attache également une grande importance à la capacité du modèle en termes d'agents intelligents.
D'une part, afin d'améliorer les capacités de base du modèle, DeepSeek a construit un environnement virtuel et synthétisé des milliers de données pour faciliter la formation.
DeepSeek-V3.2 utilise 24 667 tâches d'environnement de code réel, 50 275 tâches de recherche réelles, 4 417 scénarios d'agent général synthétiques et 5 908 tâches d'interprétation de code réel pour la post-formation.

D'autre part, DeepSeek optimise également le processus d'utilisation de divers outils pour le modèle.
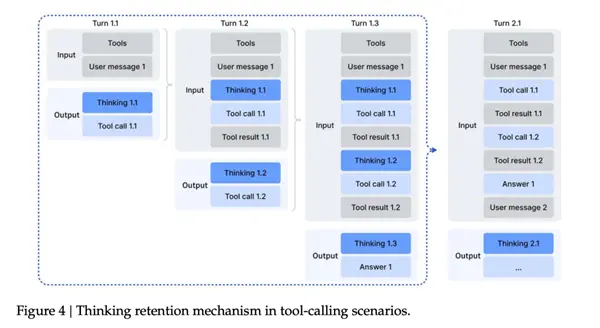
Un problème typique des générations précédentes de DeepSeek est qu’elles séparent la réflexion de l’utilisation des outils.
Une fois que le modèle appelle un outil externe, la réflexion précédente est pratiquement terminée et le travail est terminé. Lorsque l’outil revient après avoir vérifié les résultats, il doit souvent reformuler les idées.
Cela conduit à une expérience très stupide - même si vous cochez simplement quelque chose d'aussi simple que "quelle est la date d'aujourd'hui", le modèle reconstruira toute la chaîne de raisonnement à partir de zéro, ce qui est une énorme perte de temps...
Dans la V3.2, DeepSeek n'en pouvait plus et a directement renversé cette logique et l'a refaite.
Les règles deviennent désormais :Durant toute une série d’appels à l’outil, le « processus de réflexion » du modèle sera retenu. Ce n'est que lorsque l'utilisateur envoie une nouvelle question que ce cycle de raisonnement sera réinitialisé ; et les enregistrements et les résultats des appels de l'outil resteront dans le contexte, comme les enregistrements de discussion.
Grâce à ces trois étapes consistant à modifier l'architecture du modèle, à prêter attention à la post-formation et à renforcer les capacités de l'agent, DeepSeek a finalement donné à son nouveau modèle la capacité de rivaliser à nouveau avec les meilleurs modèles open source au monde.
Bien entendu, même avec autant d’améliorations, les performances de DeepSeek ne sont pas parfaites.
Mais ce que Tony aime le plus chez DeepSeek, c'est leur volonté d'admettre leurs défauts.
Et cela sera écrit directement dans le journal.
Par exemple, cet article mentionne que cette fois, DeepSeek V3.2 Speciale peut rivaliser à 50-50 avec Gemini 3 Pro de Google.

Mais pour répondre à la même question, DeepSeek doit dépenser plus de jetons.
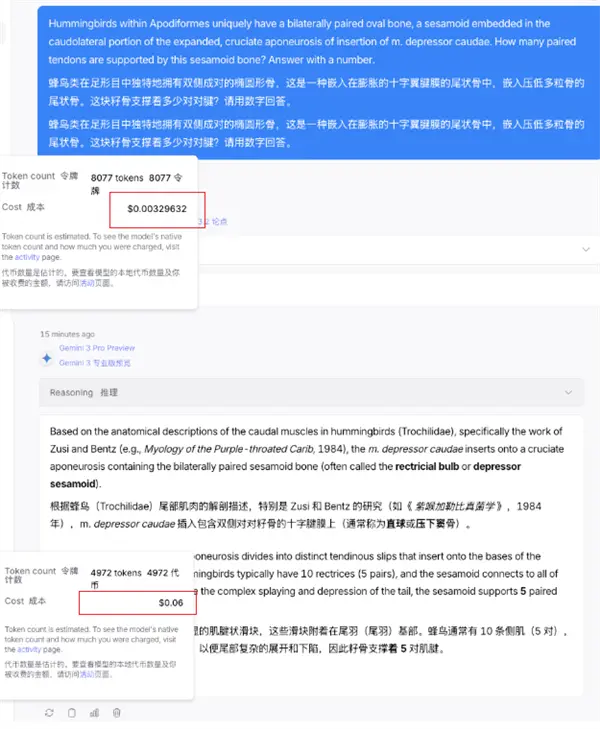
Je l'ai également testé moi-même, sélectionné au hasard une question dans la banque de questions de "Humanity's Final Exam" et l'ai lancée simultanément sur les deux modèles de Gemini 3 Pro et DeepSeek V3.2 Speciale.

Le sujet est :
Les colibris sont uniques parmi les podomorphes en ce qu'ils possèdent des os ovales appariés bilatéralement, un os caudal intégré dans l'aponévrose croisée élargie qui déprime les os multigrains. Combien de paires de tendons cet os sésamoïde supporte-t-il ? Merci de répondre avec des chiffres.
Il s'avère que Gemini n'a besoin que de 4972 jetons pour répondre à la question.

Quant à DeepSeek, il a fallu 8 077 jetons pour résoudre le problème.

Rien qu’en termes d’utilisation, la consommation de jetons DeepSeek est près de 60 % plus élevée, ce qui représente en effet un écart important.
Mais là encore.
Bien que DeepSeek consomme beaucoup de tokens, son prix est bon marché...
Posant toujours la même question, j’ai examiné attentivement le projet de loi.
DeepSeek 8000+ jetons et m'a coûté 0,0032 $.
Mais du côté de Google, ça m'a coûté moins de 5 000 tokens, mais ça m'a coûté 0,06$ ? C'est 20 fois plus élevé que DeepSeek.
De ce point de vue, je pense que DeepSeek est meilleur...
Enfin, revenons au début de l'article.
Comme l'a dit DeepSeek, l'écart entre les modèles open source et les modèles fermés s'est creusé au cours des six derniers mois.

Mais ils utilisent toujours leur propre méthode pour continuer à rattraper cet écart.
Les diverses opérations d’économie d’énergie de calcul et de sauvegarde de données de DeepSeek m’ont en fait rappelé une interview avec Ilya Sutskever le mois dernier.

L'ancienne âme d'OpenAI estime qu'il n'y a pas d'avenir en ajoutant simplement aveuglément des paramètres au modèle.
AlexNet n'utilise que deux GPU. Lorsque Transformer est apparu pour la première fois, l’échelle des expériences se situait principalement entre 8 et 64 GPU. Selon les normes actuelles, cela équivaut même à la taille de plusieurs GPU, et il en va de même pour ResNet.Aucun article ne peut être rédigé sans un énorme cluster.
Par rapport à l’accumulation de puissance de calcul, la recherche sur les algorithmes est tout aussi importante.
C’est exactement ce que fait DeepSeek.
Du MoE de la V2 à l'attention latente multi-têtes (MLA) de la V3, en passant par le mécanisme d'auto-vérification actuel de DeepSeek Math V2, l'attention éparse (DSA) de la V3.2.
DeepSeek nous montre des progrès, qui ne sont jamais singuliers et s'appuient sur l'amélioration apportée par l'empilement des échelles de paramètres.
Nous réfléchissons plutôt à des moyens d’utiliser des données limitées pour accumuler davantage d’intelligence.
Une femme intelligente se ridiculise
Alors, quand arrive la R2 ?